The pilot has been closed, results can be found in the Deliverables section.
Duration: March 2014 - January 2015
Budget: 43.000 EUR - Actual expenses: 39.000 EUR
COLLECTION OF FINAL DELIVERABLES (PDF)
The OER pilot service becomes part of the GN4 project SA8 activity starting in April 2015.
Contents: | Contact details: TF-Media mailing list is at <tf-media@terena.org> The contact person for this activity is Peter Szegedi <szegedi@terena.org>
|
|---|

Motivations
The TERENA task force TF-Media (2010-2013) concluded with a project plan to try and implement a European-level OER metadata repository service for the benefit of the Research and Education community. The fundamental principles of such a platform/service have been discussed and summarised by the task force.
There is a large interest around the global education community in establishing and maintaining OER or Learning Object (LO) repositories as exemplified by the number of existing repositories (e.g., MERLOT [2], MAOR [3], OER commons [4], Learning Resource Exchange for Schools from European Schoolnet [5]), organizations building and sustaining them (e.g., MITOpenCourseWare [6]), contributors integrating learning objects in repositories (e.g., OpenContent [7]), and users of these learning objects (e.g., Universities, Libraries). The fundamental reasons are:
- the growing educational demands in all countries,
- the limited capacity of face to face education to fulfil the demand in a timely manner (i.e. emerging MOOCs),
- the effort and cost involved to build multimedia learning materials, and the new possibilities offered by the Internet.
The main motivation for developing a metadata repository (European-level aggregation point or referatory) and an OER portal (federated single access web front-end) service would be to support the NRENs and their stakeholders (i.e. the broader Research and Education Networking Community) in engaging with open education by providing value-added support services.
The OER service intends to aggregate metadata (not the content) at the European-level and helps Universities and NRENs stepping to the next level (reach the critical mass e.g., in terms of the number of objects) towards exposing their OER to global repositories (such as GLOBE [9], for instance).
Aim of the pilot
The primary aim of the OER small project is to develop the first working prototype of the OER service (including the metadata aggregation engine and the web portal front-end) and pilot a service for the broader Research and Education Networking Community in 2014. The pilot service can then be taken over by the GN4 project for further technical enhancement and service development aiming to roll out in production.
The OER small project is to bridge the gap between the end of TF-Media (finished on Dec 31, 2013) and the beginning of GN4 (April 2015). The reason why the idea must be tested in a small project before it’s introduced in GÉANT is the fact that the critical mass (in terms of participants, support, interest, etc.) has to be gained before any sustainable service development can be done. OER seems to be a typical “chicken-n-egg” problem at the moment (i.e. without a working prototype it’s hard to gain significant interest and without significant interest it’s hard to convince the development) therefore, the OER small project has to take this initiative. The OER is not the service that the NREN community is desperate to build (e.g., like the Trusted Cloud Drive pilot was in 2012) but it’s something that the lead has to be taken on (e.g., like the NRENum.net service pilot was in 2008) in order to facilitate the development of future value-added services on top (including MOOCs and others).
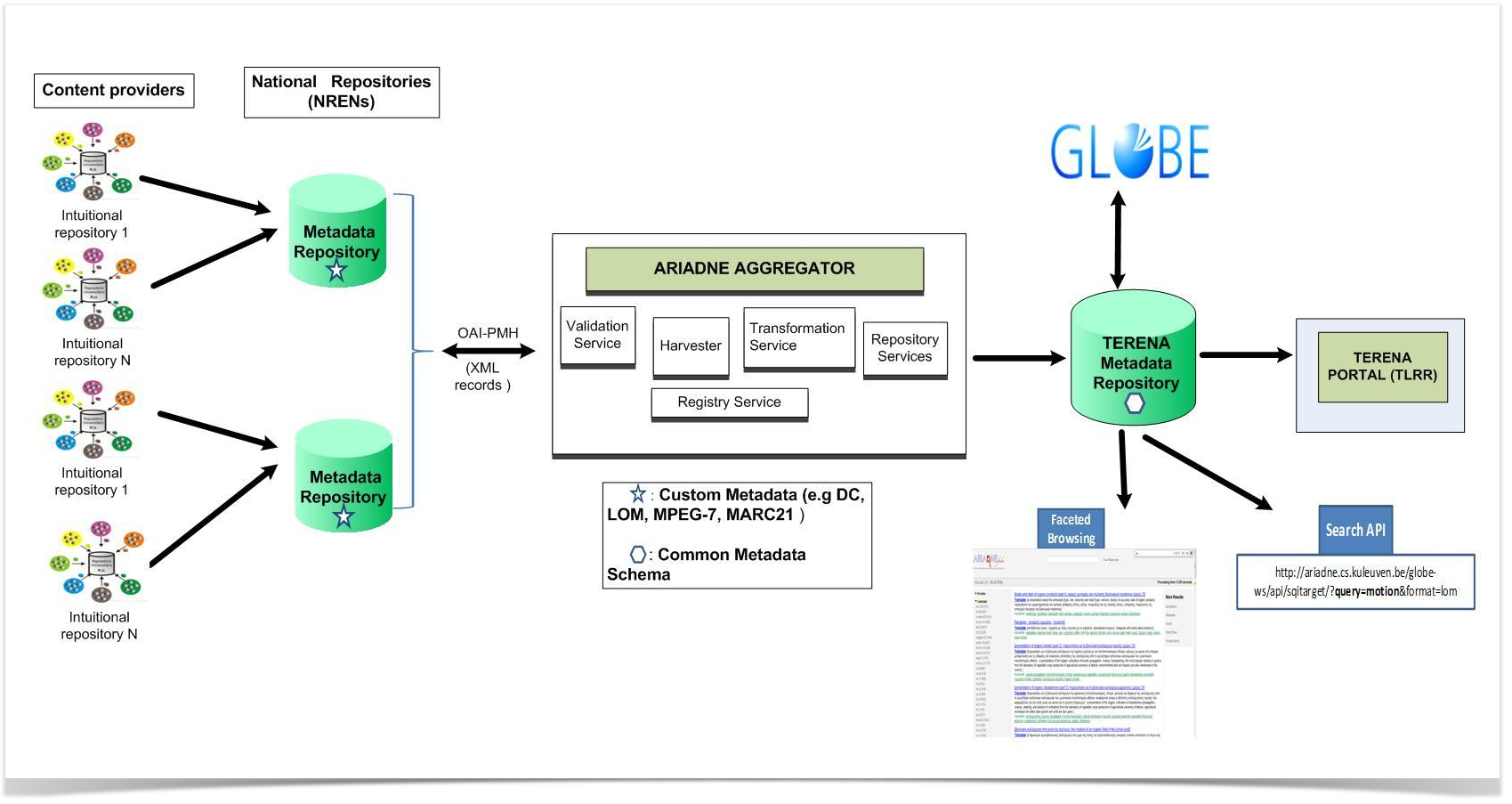
Delivering the pilot
The OER small project can be delivered in four tasks over 9 months (relaxed timeline):
- Definition of the minimum requirements for a common metadata schema (flexible, scalable. standard-based, etc.) taking into account the information model of the pre-selected “friendly repositories”. The potential piloting of a sample/reference repository with “good quality” metadata will also be considered by this task.
- Implementation of the ARIADNE-based metadata harvesting engine in the TERENA network.
- Development and deployment of the PuMuKit-based web portal front-end (web template).
- Integration of software components and piloting of the metadata harvesting, validating, transforming and publishing service.
More information is available in the pilot project description.
Deliverables
Documentation
first DRAFTs:
- OER-Initial-Study-DRAFT-v1-IUCC.pdf
- OER-Initial-Study-Architecture-v1-GRNET.pdf
- OER-PR-plan-v1-FCT.pdf
- Aggregation engine statistics:
- Here you can find the aggregation workflow results visualized.
- Here you can find the statistical analysis results based on the final aggregated metadata.
- Here you can find the Rest API service offered by the repository.The Terena OER Portal could use it in order to visualize its results.
- Here you can find a simple web based client which sits on top of the API mentioned above.
Second DRAFTs:
- OER-Initial-Study-DRAFT-v2-IUCC.pdf
- OER-Initial-Study-Architecture-v2-GRNET.pdf
- TERENA-OER-AP-draft.pdf
- Aggregation engine oai-pmh target:
- Source for other harvesters here.
- Aggergation workflow for Content Providers http://terenaoer.grnet.gr:8082/doku.php
Additional documentation:
- OER data issues by Vicente https://docs.google.com/document/d/1GXTaY1g-hLB_ySXC9sMwHruwzEhYfR5x88fquFuvy-c/edit?pli=1
Back-end engine statistics
- http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Aggregation
- http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Metadata%20Analysis
- http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/ES_Access_Stats : grnet/grnet
Fronf-end portal (demonstrator)
Meeting minutes
1st meeting - 28 March 2014 @ 10.00 CET
2nd meeting - 2 April 2014 @ 10.00 CEST
3rd meeting - 12 May 2014 @ 14.00 CEST
4th meeting - 15 May 2014 @ 11.00 CEST
5th meeting - 30 June 2014 @ 13.00 CEST
6th meeting - 26 Augustus 2014 @ 16.00 CEST
7th meeting - 16 September 2014 @16.00 CEST
8th meeting - 9 October 2014 @ 9.00-17.00 CEST (Face to face meeting in Amsterdam, Netherlands)
9th meeting - 4 December 2014 @ 14.00 CET
10th meeting - 19 January 2014 @11.00 CET
11th meeting - 28 January 2014 @10.00 CET (Pilot has been CLOSED)
11th meeting
Participants:
Eli, Vicente, Kostas, Adam, Peter
Notes
1) Kostas showed the statisitcal interface of the back-end.
- 6+1 repositories are harvested using both RSS and OAI-PMH protocols. Public iTunesU targets are also harvested via RSS.
- Documentation for content providers are available. More explanation to them is needed on how and where resources are not harvested or filtered out.
- All together about 22k resources are harvested of which 12k are filtered in (i.e. shown in the portal).
- 4 languages are available: English, Spanish, Hungarian and Greek (Protuguese is coming)
2) Vicente showed the front-endportal.
- Categories based on subject field, Most viewed and Recenty added lists on the front page.
- Both full text Google search and PuMuKit-based faceted searches are available.
- Embeded player is not always possible (depends on what the repository owner provides)
- Videotorium subject fields need to be translated
- Video duration is not available everywhere
- Some glitches here and there but good for a demonstration
Adam explained the vocabulary that Videotorim use for the subject element: http://videotorium.hu/en/categories
- Translation between this vocabular and the UNESCO vocabulary used by the GÉANT OER aggregator can be done. Adam looks after this.
- In general, we have two options: a) ask the content providers to comply with UNESCO, b) provide translation. TBC.
3) Peter elaborated on the next steps
- Pilot is considered to be done. KPIs all met. Will be reported to TTC by Peter.
- Final documentation will be compiled and distributed for comments by Peter. (Deadline: end of February)
- Portal will be demoed at the GÉANT Symposium and possibly at TNC'15
- Until the beginning of GN4 (April 2015) the team is off
- Anyhow, we should keep the momentum and discuss on the mailing list (on a volunatry basis until April)
- GN4 SA8 Task 3 will pick the results up and take the OER service to the next level.
Everyones' efforts and hard work are very much appreciated!
10th meeting
Recording:
- No duration and direct URL to media on OAI-Repos:
- OAI harvested Repos are not providing duration and direct URL to the media due to DC schema limitations or other issues( iTunesU harvested Repos are working great)
- No Licensing info:
- Only copyright owner info is coming from the agregator, no licensing info for any object
- Deleting strategy:
- A deleting strategy should be defined. When should be an object deleted from the portal´s DDBB ? The first day it's not included in the agregator feed ? (all paradata and link to the object will be lost). We recommend a "soft-delete" strategy (not included in the current development).
- VIDEOTORIUM: No Subject info
- No subject information available from VIDEOTORIUM, no iTunesU or UNESCO Codes available.
- A Requirements document is needed for new repos willing to join (specially for non iTunesU ones)
- Static Info pages needed
- Info, FAQ, About and Contact pages are just mockups. Real info is needed
- Home page should stress the fact that this service provide access to OERs from diverse sources. We need a marketing moto at the top of the home page "Discover multimedia open educational resources from XXXX organisations" or "XXXXXX Open Educational Resources from XXXX organisations at your hands"
- the portal has two many menus. I would propose to have a more clean design with a single main menu
- the main menu contains links that are more suitable for footer. The main menu should have only links related to content discovery i.e. browse, search and advanced search and the About
- we could add some nice logos of the data providers and some basic info http://terenatv.media.uvigo.es/en/library/abc.html
- it is confusing that some of the resources open in the GEANT OER and other directly on the original site
- mainly Spanish content promoted in the home page. This is not very good for a federation service.
- the menu on the left side menu is confusing. I would propose to have a top menu with main options like Browse, Search, About and transfer the top menu contents in footer
- Recorded date field seems not to be correct. Is this really recorded date or ingested into the portal date?
- Add friendly names for the Language filter and not ISO codes e.g. en, es
- Could we have facets with statistics for each value e.g. English (10)?
- using term agriculture in http://terenatv.media.uvigo.es/en/buscador/index?institution=all&lang=all&subj=all&year=all&duration=all&material=all&search=agriculture I get 8 results while using the search box powered by google I get 2. This is confusing. I would strongly recommend to use the Pumykit search mechanism in both cases
- footer content seems not related to the scope of the project
- add how to contribute link with guidelines for the providers on how they can provide their content and link this section to the wiki page that Kostas has shared
- while we are showing audio as an option in the format filter there are no results and the term "no videos" is used. Maybe we could use the term "no resources" instead
Promotion examples from Nelson
I’m sending this email with some of the communication examples you asked me to create during the last year.
You can see attached 3 different posters in A4 format that can be used to promote the service around the world, mainly to our main target, the NREN’s.
3 Key Messages:
1- Are you ready for open education?
2- Are you ready to connect to the Géant OER?
3- Are you ready to publish your content with open licenses?
These examples can be easily promoted by email, newsletters or as a printed version in conferences and institutional events.
I think it would be important to create a strong corporate identity (name, logo, slogan), before the project release as I wrote in the communication proposal. In my point of view these elements will be the key to promote the service and to engage users with our brand(Géant OER). I think they should be created and included in the different promotional channels since the beginning of communication process.
A4_Are_you_ready_for_open_education.pdf
A4_Are_you_ready_to_connect_to_the_Géant_OER.pdf
A4_Are_you_ready_to_connect_to_the_Géant_OER.pdf
9th meeting
Participating:
Peter, Kostas,Vicente, Eduardo, Giannis, Eli
Agenda:
1. Summary/Update - Current Status
2. Focus on the Content, Functionality
3. Update on the back-end engine
4. Front and back end interaction
5. Timeline
- - -
1. Current Status
Vicente: working mainly on data structure, adapting the PUMUKIT structure to the application profile
working on the import scripts - not as straightforward as expected; modifying the scripts all the time - related to the structure and the vocabulary
[demonstrates JSON file example: issues with specific fields, supposed values, file formats do not match - need a translation at an aggregation level, media format doesn’t appear, strange language codes - or appear to be English, but isn’t - language codes should be translated, lack of numeric codes, etc.] - issued needed to be solved in order to get good data
Peter: problems related to the metadata translation - should be translated into one format or schema
Vicente: some issued should be fixed at the repository level
Peter: proper translation needed, metadata not exposed by local repositories - a) ask them to change that, b) try to translate it automatically
will have to tackle that later on
Vicente: our own repositories - improving the data exposed in order to make it easy to harvest, but data coming from iTunesu - cannot count on cooperation with the data provider; translation should be done at the repository level
we have all the tools, just need to focus on improving the harvesting process
Peter: can compare the local repository and the one harvested - enough for us to prove that it will work
Kostas: the phase of transformation is problematic, we don’t know what are the elements used from others’ perspective, might have problems with mapping the local elements with the elements of TERENA OER
Peter: thumbnail gets lost for example; need to look for the basic fields we agreed on
Kostas: last time we were harvesting there were no thumbnails
Vicente: part of the collection, not of the item, but we are not working with collections now
Kostas: could harvest information where thumbnail is a part of the item
Vicente: need to interact more to solve minor issues
Kostas: send me the list of issues
Vicente: regarding the portal - some objects have been harvested, currently the URL exposed is not the direct URL to the media, but the player page (can be changed)
categories, filters
search - first implementation
information available at provider level, possible to harvest it
2. Focus on Functionality
Peter: functions need to work, else the end-users will leave, if something doesn’t work, should not be on the pilot version; ok to put new features in as they become functional
Vicente: this is work in progress, users wont be exposed to anything that won’t be working, functionalities there for demonstration purposes only, will be removed
- - -
Peter: Kostas, once the translation is done, others will work or are there differences?
Kostas: main issue is translation, has to be done together with Vicente and his team
Peter: scalability of this process in the future - tedious manual approach for now for every repository; next repository will have to be treated the same? doesn’t seem scalable
Kostas: difficult to create a transformation file for every provider, will take time
Giannis: the first version is for the internal consumption, but later it will be important to communicate to the data providers willing to join
Vicente: maybe institutions willing to do what is needed, but might not; or we can learn to harvest the apple feeds properly
Peter: would not fixate too much on the apple one, we want to connect different sources
Giannis: need to have some educational metadata, else we will just replicate the iTunes harvesting mechanism; need to understand the semantics of the metadata - main problem, else can be corrected
ACTION: Vicente to send a detailed list of issues to Kostas
Eli: need to see how many hours Kostas will need for every repository 5-10 hours - worth it, else need to consider
Giannis: either remove the subject from the front end, or not use metadata that has no subject element - will apply to many elements
Eli: if we will see that we need more go arounds to fix something, maybe we can discuss the technology aspects in the next phase
Peter: we will have development time in the next phase (GN4, April next year) - Kostas will be spending a lot of time working on it
- - -
Timeline
Peter: one more meeting before holidays or better in January? Can also follow up individually - (will be back on 5 January)
Giannis: specific collections from the iTunes site - who is responsible for those collections?
Peter: iTunesU was identified as an escape for now, but need to focus on the local repositories - everyone in their own countries should look for it, happy to do that in the Netherlands (also need to address the language question later)
Giannis: i will look for Greek collections
Peter: next meeting in January
Software fixes by Kostas
- Improved the mappings from native RSS Itunes U metadata and DC to the LOM based OER Application Profile.
- Extended the RSS Harvester to gather information from RSS Channel element and inject it to each and every element where the specific info is missing for example the itunes:image.
- Extended the seach API to offer duration, format and contributors name.
- The elements' possible detected languages are limited to en and es.
- The dates issue is not addressed(and it will be very difficult to be addressed since there is a great diversity in the way dates are defined)
- A new repository(Standford) is added.Peter sent it to me before sometime ago.It is RSS Itunes U based.Check the dashboards for more info.
8th meeting face-to-face
Attendees:
Vicente, Eli, Giannis, Kostas, Nelson, Adam, Tibor, Antonio, Jean-Francois, Sigita, Peter
Presentations
- OER Pilot: Value proposal, Concept, Focus by Peter
- OER Pilot: Components, Features, Project Phases by Eli
Links and Attachments
- Demo discovery service for the aggregated metadata http://terenaoer.grnet.gr:8080/terena-finder/#/educational/search/?q=*
- Visual analytics for aggregated metadata http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Metadata%20Analysis
- Visual analytics for each step of the aggregation engine http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Aggregation
*AGREEMENTS*
0) Project phases:
- Phase 1 (Version 1.0) - until December 2014 (TERENA pilot funding)
- Phase 2 (Version 1.1) - Jan 2015 - April 2015 (no extra funding)
- Phase 3 (Version 2.0) - April 2015 - May 2016 (GN4 T3 Phase 1 funding)
2) The primary focus is on higher education and research (HEI&R) content repositories managed by an NREN or connected institutes.
3) The media type is "multimedia" (lecture recordings, conference recordings, learning objects) that includes video, audio, animation and recorded content stream but excludes still pictures and/or documents in Phase 1.
4) Two usage scenarios:
a) User starts searching globally using Google search service.
- GÉANT OER web portal indexes meta-data so Google finds it.
- User goes to GÉANT OER portal from Google and continue/refine searching there. *ADDED VALUE*
- When the users finds the content, goes off to the local repository or use the embeded player if available (learning process starts).
b) User starts searching in the local/institutional repository.
- Unsatisfied by the results but there is a GÉANT OER search widget made available by the local portal (?) *ADDED VALUE*
- User searches in the widget that directs to the GÉANT OER portal.
- As soon as the content is found and the learning process starts, user goes off to the content repository or use the embeded player if available.
5) Portal features and functionalities in Phase 1:
- Display thumbnails of multimedia objects (i.e. video, audio, animations, but no still pictures or images)
- Include direct URL to the object where available. Use embedded player or naked player provided by the source repository where possible.
- Display metadata based on the application profile (mandatory/recommended/optional) agreed by the pilot group.
- Handle Creative Common licensing.
- Facilitate browsing and faceted search (i.e. organised in predefined categories based on closed vocabulary e.g., UNESCO subjects)
- Implement simple and advanced search; either based on the back-end engine search functions or the Google search engine restricted to the portal. Develop a roadmap for the advanced search functions and the pilot service evolves.
- Implement sharing, primarily via e-mail and social media platforms.
- Apply responsive web design for proper scaling and rendering on mobile devices.
- Deal with user registration; only LDAP-based local registration in the first phase but be ready for Single Sign On (e.g., social media login) and access federations with eduGAIN.
- The portal interface language shall be English; the metadata language should be English if available or the original language of the content.
- Include information pages such as: About us, Help, Contact, Terms & Policies, Disclaimer.
6) Portal features and functionalities in later phases (TBD):
- Federated access and membership management.
- Multi-lingual user interface and customization option.
- Web access for disabled.
- Paradata collection and handling including: rating, commenting, popular items, suggested items, dynamic tag cloud, usage information, quality issues.
- Peer review functionality.
7) List of good quality repositories to start with:
http://tv.uvigo.es/
http://tv.campusdomar.es/
https://educast.fccn.pt/
https://cast.switch.ch/
University of Manchester
iTunesU RSS targets...
YouTube channels...
8) Metadata application profile need to be finalised and provided to the connected repositories to comply with. This could be a mix of IEEE LOM and DublinCore. Keywords are not mandatory. We need help from the providers to translate their metadata schema/vocabulary properly.
*ACTIONS*
I) On Giannis to finalize the metadata application profile. This should be a clear recommendation to the connected repositories.
II) On Kostas to investigate iTunesU RSS harvesting as well as YouTube channel harvesting.
III) On Vicente to start developing the web front-end portal based on the agreed feature set above.
IV) On Nelson to work out a provocative promotion campaign for institutional repositories saying: "Are you ready for Open Education?", "Are you ready to publish your content with open licences?", "Are you ready to connect to the GÉANT OER?"
V) On Peter to finalise and administrative and contractual details.
VI) On ALL to contact your friendly institutes and ask for the iTunesU RSS feeds (if not the OAI-PMH target to their repository). At least, one university per country represented in the OER pilot Pass it on to Kostas.
*NEXT MEETING*
I think, we need an on-line meeting in two weeks to speed up the process as now we have a good understanding and consensus. I'll circulate a Doodle poll soon.
Notes from Giannis (GRNET)
- TERENA will join Dante http://www.geant.org/Pages/Home.aspx
- We can have a small delay until March because the geant 4 will start on 1/4/2015
- Rename to Geant OER pilot
- We need to have federated identity for all the researchers and teachers to ensure the SSO
- For the first we could have SSO with google but for the next phase an approach based on AAI
- We could have a bridge for the moodle at the level of pymukit
- For the type of content that we will have: video, audio, moving pictures, but not still images
- Mooc builder and lms are potential customer and not the providers
- Searching inside the video should be in the future phase. We need to include a manifest element in the data model and this requires significant extra effort
- We could try to extract the duration automatically from the data provider but this could be very time consuming. Check if duration is provided in itunes data model.
- UGC not on the portal but through a separate repository tool
- Categories as they are in the uvigo TV
- For the subject we agreed to use the UNESCO classification
- Google custom search is very good way to attract people from Google because it is indexed directly the metadata.
- We need to make the metadata to be indexed quickly by google
- Contact Uvigo to decide if thumbnails will be generated at the portal
- Add embed functionality
- User interface in English. For the metadata English if available and show other lang else
- Symposium of grant plus in Athens on February
- Easy2rec a tool for the teacher generated content
- An interesting tool for connecting pymukit with opened moocv platform
- A nice idea of using iTunes RSS
- We can harvest content from YouTube edu
- Content providers: Start only with uvigo, campus do mar, maor and switch. Extend to other through iTunes rss. Select the key
- Show on the portal only recommended and mandatory metadata elements
- Moodle module based on pymukit
GRNET actions
- Disable the old solr API that we have - Kostas
- agree on the new sync API between aggregation engine and portal - Kostas and Uvigo tech team
- Check the switch repository has implemented the new OAI target.
- Check if the subject is present in uvigo OAI target. If not ask Vicente to add it - Kostas
- Contact Uvigo to decide if thumbnails will be generated at the portal - Kostas
- Next Steps for the aggregation engine
- Finalize the new schema - Kostas and Giannis
- XSD - Kostas
- Extend RSS - Kostas
- Harvest - Kostas
- Provide the XML or json files - Kostas and Uvigo
7th meeting
Attendees:
Adam, Vicente, Eli, Peter, Sigita, Kostas, Giannis, Nelson
Recordings:
http://emeeting.campusdomar.es/recording/a18776711ec9a1ba563a68ecde656eef
Minutes:
1) Status of the initial study, comments by GRNET, Wiki content, etc.
V: the two documents are mainly definition of the service - lacks info what the system will look like and what features will it provide
P: you don’t font the info needed for development? - clear concrete feature list to be determined during the face-to-face meeting
E: the players of the project will be clearly explained in the next version of the document (to be produced in a few days) - looking for input, comments
V: used to working on user driven basis - need to understand what the users are expecting; need to check user specifications (not to be fulfilled at first, but need to make sure that the architecture is ready to be updated for the later versions)
K: […?]
P: Kostas already working on aggregation of the metadata, had a look at the status and statistics - must be part of the document (screenshots, etc.) - to understand what features can be/cannot be implemented; architecture has to be flexible for when we are ready to implement more
P: metadata - a must, paradata - might be left for a later stage
K: issues with getting repositories to expose their paradata
G: the only source of paradata - OER portal - maybe more in the future
(if we want paradata, this has to be collected through the portal)
V: the system currently only collects statistics, but ratings are easy to add
G: better to have the users express this kind of requirement
G:should professors be the primary persona? maybe would be good to have one primary focus.
P: two groups - end users and system admins, would not split those groups further
E: risky to use interviews with professors - can focus on very narrow solutions, need large scale interviews, need to understand what is the state of the art in the world, find more common, most relevant features
V: in any case, need to be connected to the prospective end-users - maybe a more complete survey is needed?
P: continuous feedback necessary
G: 20-30 interviews needed, but due to time limitations a prototype is needed - create the first version and then ask the users for feedback
G: made a new version of the study, no major changes only improvements and small additions
E: integrated most of the comments, got comments from more professionals (mainly professors) - new version will be circulated within 10 days from now
ACTION: Giannis will send his updated version, Elis will prepare a draft for the face-to-face meeting
2) Web front-end development
P: work for Vicente’s team will be defined during the face-to-face meeting
V: need a definition asap - features and structure; also need a contract asap to define man power
P: will start an e-mail dialogue with Giannis and others to give you more clarity before the face-to-face meeting and also start working on the paper work (contracts) now
E: study document contains quite some information about the features etc. that can be used
P: the first version of this application profile should come from Giannis and Kostas
G: we can provide first proposal for that, but its an exercise based on the real needs of the users
V: use the user stories for the exercise
P: plus personas described on the wiki
3) Face to face meeting preparation
P: will prepare an agenda, full day meeting (9:00-17:00), send your arrival times, dinner possible the day before; will need to make decisions during this meeting, so good agenda and good preparation is crucial; booking hotels might be difficult - will prepare some recommendations
4) GN4 Task 3 update
5) Position paper of NRENs on Open Education
6) Priorities, deadlines, AoB
G: Application profile deadline - before the face-to-face meeting?
P: definitely - need to have the new versions of the study from everyone, will try to incorporate work from the wiki, and the application profile; will come up with a draft agenda as well and send it out for comments
V: comments for the user stories are welcome - can be found on google.docs
6th meeting
Attendees: Eli, Giannis, Kostas, Nelson, Peter, Sigita
Agenda:
1) Contributions from IUCC and GRNET (Eli and Giannis)
2) Face to face meeting (Peter)
3) Aggregation engine update (Kostas)
4) GN4 SA8 propoal (Peter)
5) AoB
Minutes:
1) Contributions from IUCC and GRNET (Eli and Giannis)
Peter: happy with the content of the first draft - should be merged together to have one overview on the pilot
- IUCCs contribution - good overview on the current state and describes the services
- GRNET - focused more on the technical details
Eli: What we have in our doc now (welcomes feedback):
- 1 part: introduction of the OER, definition; move to the background of the TERENA OER project and motivation; at last what kind of projects there are;
- 2 part: explanation of what kind of project TERENA project would be.
- 4 LAYERS:
1. Metadata (what kind is needed, based on TERENA survey?)
2. Paradata (comments, user ratings, tags, etc.)
3. Connectivity (connected to libraries, other depositories outside of the main project)
4. Community (social media, creation of the community)
Some of this will be done in the first phase, some in the second.
Wide project, narrow core - unique project, dealing with a lot of issues on the European level
Will be able to connect with many organisations outside of the core of this project
Survey - very important, could be added as an annex or otherwise integrate.
Document also sent to some OER experts
Peter: How can this be merged with the GRNET contribution?
Giannis: Comments on IUCC document: Good basis
Would be good to provide the scope at the beginning of this merged document
3 main objectives:
- provide the specifications for the system, will provide the design and developing phases of the project
- clear specifications most important
- and that it can be used for communication
For specifications: user stories, personas, mockups -> done already, so can easily be included
Q: mandatory subject element - proposed or strongly recommended? we don’t have the subject element in many cases
Eli: all the second part of the doc is opened to discussion, mainly the metadata; some based on the survey; metadata field taken from one of the documents discussed in the past, but it has to be edited together need to understand the scale of the project and other relevant details
Survey and previous discussion can/should be added to the document
Giannis: agree that it could be an appendix together with other long tables
Q: Nothing mentioned about vocabularies?
Eli: if we use the (LOM?) then cannot use anything other this is something that needs to be discussed knows a specialist that can help
Giannis: should include a section about this in the document include some options that we have this part can be connected to the user stories and search and browser functionalities
Eli: vocabulary is relevant to how you add the materials to the system - technology issue, how to implement it, and the filters - might be the best if we can have as many as we can filters and vocabulary
Giannis: also the need to define mappings and to make transformations - need to decide whether it will be done automatically or manually - if manually someone has to take over this task
Eli: how many layers? 2 or 3? effective for the users
Giannis: this can simplify the work but the work of transportation will still be needed this has to be foreseen for the future
Peter: this issue can be left for the face to face meeting - agreement on this is needed
Giannis: we need to define the reference classification at this stage - for as many layers as needed
Peter: maybe skip for phase one, introduce later
Giannis: educational levels - could we also target vocational education?
Eli: should be open to everybody so we can say “higher education and any other users”
Peter: we narrowed down the scope - education in general, focused on higher education (primary focus of most of the NRENs), and focus on those, where the NRENs are active in - could be extended as a next step
Giannis: target audience - does not come up in the proposed schema
Elis: target audience is important to users in the higher education and outside; open to discussion and we have to see what you can implement having a target audience filter is important in the end of the process we might understand that there is no need for this we can take it out, but i believe that it is needed can be mandatory, optional or recommended
Kostas: difference between location element and url element?
Eli: sometimes there is a difference [explains] - [url issue and other should be part of the face to face meeting]
Giannis: two cases - page where resources shown and where resource can be accessed at
Eli: has doubt about the LOM is it would be used, but those who will do the implementation should be part of the face to face meeting; need to agree on the mandatory
Giannis: maybe include a section with other options to LOM?
Kostas: Keeping the balance on the mandatory elements - nice to have as many elements as we need, but from aggregation side is makes it very strict, a lot of metadata will be dropped out, need to find a balance
Giannis: we will not be able to have more than 5-10 elements as mandatory
Eli: if we are leading the way, we need to make a standard; this needs to be discussed based on what the user will get - problem with global - almost no metadata and too much unnecessary material TERENA should recommend the standards
at first maybe 5-10 mandatory fields, but recommend to have more
Giannis: agreed, but need to keep the balance
Giannis: what are the dates of the phase 1&2?
Peter: TERENA pilot - phase one is the one we can implement, the rest will be the “afterlife” of the pilot, in GN4
2) Face to face meeting (Peter)
Peter: need a date
Nelson: who will pay for this?
Peter: preferably your org pays, but could be covered by TERENA (limited number of trips)
Option 1: 25-26 September
Option 2: after 7 October
Will set up a doodle.
3) Aggregation engine update (Kostas)
Currently the Ariadne engine is harvesting about 13 repositories. The detailed statistics can be examined at
http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Aggregation
http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Metadata%20Analysis
4) GN4 SA8 propoal (Peter)
Peter have been appointed to be the Activity Leader of the new SA8 service activity on "Real-time communications and Media Management services" in GN4 (starting in April 2015).
There are three tasks:
- Real-time video services (former eduCONF)
- WebRTC roadmap
- OER development
Task 3 is to take over the TERENA OER pilot results in April and develop that furter toward a production service of GÉANT. Kostas (GRNET) will be the task leader of that.
5) AoB
Nelson produced a DRAFT plan for the promotioal activity of TERENA OER. The document will be circulated for further comments.
Peter noted that the pr and marketing efforts must be aligned and incuded in the pilot early on. Nelson's contribution is very much appreciated and will be part of the initial study.
5th meeting
Attendees: Eli, Giannis, Kostas, Adam, Nelson, Peter
Agenda:
- Initial study kick-off
- AOB
Peter summarized the actual status of the pilot. We have now two contracts in place; one is with IUCC primarily to coordinate the initial study preparation and the second one is with GRNET mainly to develop and deploy the metadata aggregation engine at TERENA.
Eli (IUCC) is coordinating the study preparation, everybody is invited to contribute. External experts will also be consulted. Giannis (GRNET) will contribute to the metadata schema definition. There was an agreement to use IEEE LOM with about 8-10 mandatory and other 10 optional fields. Kostas commented that a widely used/known schema should be selected in order to be able to aggregate good quality metadata. Metadata translation will be needed anyway. It was suggested to pull a meeting dedicated to the metadata schema discussion. Eli is responsible for coordinating that. Sharing of documents and information via Google docs is preferred.
Giannis and Kostas (GRNET) reported that they have started to contact the potential content providers. 13 NRENs and other organizations have been contacted and requested to harvest and analyze their metadata via OAI-PMH protocol with mixed success. Some repositories only support RSS though. Work is in progress… Some analysis will be available by 25 July and the metadata schema contribution will be ready by 1 August.
Peter (TERENA) said that the discussion about the web portal front end development is progressing. UVigo agreed to lead that part of the pilot. Contract will be in place by September. We have to come up with clear requirements and recommendations for the web front end interface by then.
Nelson (FCT) would be happy to contribute to the outreach and dissemination strategy part of the study. He could also be our liaison person to TF-CPR. Peter will put him in contact with TF-CPR.
Peter will Doodle for the potential dates of a face to face meeting where the results of the initial study and the next steps can be discussed and agreed. The meeting most likely will take place in September in Amsterdam.
4th meeting
Attendees: Eli, Kostas, Vicente, Rui, Adam, Antonio, Peter
Agenda:
- Content of the Study
- How to proceed
Recording:
http://emeeting.campusdomar.es/recording/4bcc81ced2cb65ced4c3f95720654625
Notes:
Peter predented the DRAFT table of contents for the Initial Study and opened the floor for comments and discussion.
Coordinator: IUCC
Contributors: GRNET, UVigo, ISEP
Deadline: 15 August 2014
-----
OER state-of-the-art and outlook
1. State-of-the-art content/metadata repositories/referatories and their functionalities
1.1. Repository strategies and policies: National, European and global initiatives (GLOBE, openeducationeuropa.eu, etc...)
1.2. TERENA OER differentiator; primarily focusing on higher-education and research (big science groups)
1.3. Classification of the user community and their requirements in 3-5 years (end-users, e-learning service integrators)
2. Architecture design
2.1. Information model and metadata schema, recommendations (mandatory, optimal)
2.2. Standards and interoperability
2.3. Harvesting engine, standard protocol set, technical features
2.4. Preliminary analysis of connected repositories
2.5. User interface and web portal functional and usability requirements
3. Promotion and outreach
3.1. Engaging users and producers
3.2. Legal and rights issues
-----
Eli commented that Chapter 1 should give the bigger picture (open education, MOOC, etc.) and the whole study should narrow down to the specific recommendations and requirements. We have to clearly understand the current trends in education and response to that. Vicente added that first we should describe the "idealistic" picture reagarless of the existing tools and then in Chapter 2 we should take into acount what tools we can reuse and see how close we can get to the idealistic solution. The closer the better.
Antonio commented that the understanding on the typical workflow how professors develop courses and use tools (such as Moodle LMS) is the key. The proper liaison with the various institutional repositories (mostly DSpace-based in Portugal) is also important to support the federated model. Trust is the key for quality assurance (the use case of sexual education was mentioned where finding good quality educational content is difficult). Integrating with AAI and developing functions such as the peer review system could maintain the trust relationship with content providers.
Antonio and Vicente offered help to incorporate the professors' view and review the study from the education perspective.
It was also suggested to use Google docs for the collaboration and distribution of the study.
Peter noted that the administrative steps (contracting, etc.) will be done shortly after TNC2014.
3rd meeting
Attendees: Eli, Giannis, Kostas, Rui (partly), Nelson, Adam, Peter
Agenda:
- Look at the Personas
- How to transform requirements into basic features for both the engine and the web portal
- Reference repository <=> reference web portal (demonstrators)
Notes:
Peter summarised the key requirements comming from the Personas proposed at the last meeting. The group made an effort to categorise the Personas. Two main categories have been identified:
a) End-users; such as students, professors and researchers (i.e. A, B, C, D, G, K)
b) E-learning administrators; such as service managers and system/service integrators (i.e. E, F)
Giannis suggested to extract the requirements from the Personas and identify the list of "top problems" that we are trying to give an answer to.
Attendees had a consensus on writting an initial study that leads to some clear design requirements concerning both the aggregation engine (back-end) and the web protal (front-end).
Such a study must be done by mid August 2014 as the latest so that the necessary software developments and deployments (recommended by the study) can be done by the end of the year.
Eli (IUCC) agreed to coordinate the production and delivery of such a study and Giannis (GRNET) offered to contribute to the harvesting engine related technical parts of the study. Adam (NIIF) and Nelson (FCCN) will check back whether they could also contribute to the study, provided that the draft table of content of the study is agreed.
The attendees did a short brainstorming on the potential content of the study. Peter suggested that the study should start with a technical overview on the state-of-the-art content repositories and their basic characteristics. Giannis said that the overall picture should also be described including similar global (e.g., GLOBE) and European (e.g., openeducationeurope.eu) initiatives and their relation to TERENA OER. The basic information model, metadata schema, and protocol set should also be suggested by the study. Contribution to the user interface and the web front-end requirements is necessary. The functional description should look ahead to 3-5 years in time taking into account the latest trends in on-line teaching & learning .
The study must be delivered by 15 August 2014 as the latest, the harvesting engine adaptation and deployment as well as the web portal development can then go hand in hand base don the recommendations of the study.
The next meeting will be dedicated to the discussion on the Table of Content of the study.
2nd meeting
Attendees: Eli, Giannis, Rui, Adam, Peter, Nelson
Agenda:
- Personas
Recording:
http://emeeting.campusdomar.es/recording/a5fcb5b9c50cc97b644b159387021180
Notes:
Rui's personas were Adam, Bob and Charlene. Bob usually searches for materials in Google but the academic value for him is in TERENA OER. Bob is a not-so-experienced guest teacher who uses Moodle but needs some ready-to-use content. He values that Moodle that he knows reasonably well is connected to the TERENA OER. Charlene is the person at the university who teaches the teachers. Reusability of materials is important for her.
Displaying "favourite content" can help to find similar contents more easily. Ratings, registered user tracking (AAI) and social networking are important.
There is a difference between the monilithic LMS approach and the open MOOCs approach. TERENA OER should support both. Following the users' behaviour is important in case of MOOCs where they can alter from the default learning path. We need to know what they are searching for.
Eli commented that the community and social aspects are challenging. We need to focus on the repositories with good quality metadata, then allow the collection of paradata (remarks, rating, comments) and finally we can bring in the networking/social aspects.
The confidence of the users can be gained by trusted information sources, good quality metadata, additional paradata and maybe in the future a peer review system.
We should be able to integrate Moodle LMS with TERENA OER by the end of the pilot.
Next step: We need to transform the requirements (coming from the Personas) into basic features
Some administrative aspects of the pilot must be clarified:
- Roles and responsibilities of the participants (to be discussed off-line)
- TERENA funding schema (contract template will be sent by Peter)
- Community must be informed about the OER group but not yet invited (oer mailing list will be created by Peter)
Personas:
| Dean | Dean is a college professor that wants to enrich his teaching process and materials. When he searches the internet for materials for his class, he encounters several problems: Google offers many resources, but without details or depth search most of them are irrelevant; OCW-C offers full courses that he doesn't need; GLOBE is similar to Google, only it offers even more information than Google – and that information is also, at times, irrelevant. Finally, he finds the OER-Terena site. There he finds varied resources (HE repositories ) and materials. Using the depth search and the detailed metadata, he finds relevant and useful materials to enrich his class. Moreover, those resources have detailed explanations on how to use them and when. With those resources, Dean creates new teaching process that are tailored to his class topics, integrates online and offline teaching and learning. |
| Giannis | Giannis is a Data Scientist working in the National Technical University of Athens. He performs statistical analysis on big data in the medical domain. Giannis has found various references on the web about how the R package can be used for the analysis of big data. He seeks for learning resources and open courses on how R package can be used for big data analysis. He finds some interesting resources using Google and youtube but the discovery experience is not good mainly due to big recall on the queries that he performs and non relevant resources. He is also checking Coursera about available courses on this topic. The discovery process is time consuming and content is not always open. He learns about the Terena OER service and he visits the portal. At the landing page he sees different target groups and thematic categories. He is able to search using free text but also to browse content by topic, resource type, target audience. He can preview some more information (metadata) about the learning resource and access the actual learning resource (video, document, online resource). |
| Kostas | Kostas is a Software Engineer at a research center developing the tools for research projects (EU and National). He is asked to work on a new project that will deal with cloud computing and big data. He has a small previous experience with cloud computing and big data technologies. Kostas is looking for learning material on cloud computing and big data. He wants to develop his skills in cloud computing (e.g. Virtual Machines, virtualization, linux administration etc) and big data technologies (Hadoop, MongoDB, Elastic Search etc). To that end he is seeking on available course and learning material about cloud computing and big data. Although he finds interesting material using Google, youtube, coursera and sites of Universities there is no a single point at a European level that hen can access and discover such resources. The discovery process is time consuming and content is not always open. He learns about the new Terena OER service and he visits the portal. He is using the free text search functionality. When he starts typing "cloud .." the system already suggests some keywords for search. He selects a suggestion that is close to what he needs and he study the results. He is able to filter the results based on media type, audience, licenses and provider. Hen can preview the metadata of the learning resource and access the content. He can mark the content as favorite to study it later and share it with his colleagues in Facebook, twitter etc. |
| Adam | Adam - Undergraduate Student in Biology Adam wakes up every morning early. After a quick jogging in the morning he likes to go through the topics of the subjects that are being covered in class. Each day he searches on google and on the TerenaOER information about 5 key subjects that he selects for each day. On google he tries to find documental and "generic" information about the topic as it is a general search engine that will provide all sorts of type of information, from news to blogs, from assorted webpages to scientific documentation. Sometimes there are some interesting videos on Youtube or TED. But, because most academic content is under "closed" environment on LMS, Adam also searches on the TerenaOER which indexes all the information around Europe. Using the search expression he can identify other contents that are hided from Google. He also knows that this content are made from academic faculty and, of course, are much more reliable. Often he uses some of this information to his homework assignments or reviews lectures from faculty members other from his own university to grasp different viewpoints on the matter. Usually he uses his tablet to search because it is just more convenient that the laptop, but once he founds something interesting he favorites the content for later viewing on the laptop. |
| Bob | Bob - Teacher at Technical Politechnica Technical Engineer for more than 30 years now, Bob has recently joined Technical Polithecnica as a faculty member. He is very experienced user on IT and has used several times commercial services to support his training activities on his former job. But on public university context everything is different. He is supposed to use Moodle (an open source LMS), that he knows little about, to create a course to support his new course. Feeling lost, unable to find anything on the web and with little time to produce the content course. Some colleague has told him about TerenaOER website where he should be able to find useful stuff... Once he accesses the portal he searches for the content using a text expression, selects the creative commons rights, accessible content, in English (or with captions in english) ask to list first the Moodle's SCORM packages and the results start to appear. He is really impressed about the results, as they are listed from several sites across Europe. The first couple results are, in fact, packages he can introduce directly on his Moodle and tweak with. The rest are several contents that he can consult and retrieve the reference to directly use on his Moodle LMS. He favorites the content that he has used and that increases the rating of the content itself on the directory, that will help others to find this higher quality content. |
| Charlene | Charlene - e-Learning infrastructure manager at University e-Learning service at University provides a content support service to its faculty. Every day several teachers "spam" Charlene with requests to incorporate content on his courses. Un-fortunatly, most of them don't have a clue on what its needed to push content into the LMS, but the requirements are great... Charlene has given a great service over the years and people now expect interactive simulations, quizzes that are response aware and guide students,... Charlene has done lot of things in the past, but don't have much time to do it anymore. So, she tried to get some help! She joined a facebook group where people, like her, have lots of material and lots of requests, but no time to do it. But nothing really happens. References are lost, unable to get a good index, no response from others… One day, Charlene receives an e-mail from Peter Szegedi (TERENA) inviting her to look at this new site, the TerenaOER. Charlene immediately understands that this could be a great place to share her creations and, at the same time, get creations from others. She then goes to facebook and challenges her "peers" to post their content on the TerenaOER. She goes through her repository website where she has gathered all her creations and register them on the TerenaOER website. She knows that others will post also their own creations and life will be much easier for everyone in the future. She monitors her content popularity with the ranking tools provided (ranking, favorites, comments) and, times to times, she gets some feedback from teachers that have found useful content and students that have learned something new based on her creations. |
| Frans | Frans - Media services manager at Decent but Small University Frans manages the media services for the small University that includes a simple local content repository (using an open-source software) with a home-grown portal front-end tailored to the various faculties' needs. Frans really likes the media portal and its features as he was one of the lead developers of the portal and he knows everything about his local user community. Although the users are also happy with the portal but the actual contents that are available in the local repository are not so good quality and they wish to have more enriched learning objects available. Frans heard about the TERENA OER service and knows that the European level aggregation engine harvests open contents from various repositories across the community. Frans offers to contribute with the metadata of his university's contents to TERENA OER and in return he directs his home-grown portal front-end to the TERENA OER aggregation engine API in order to present more targets to the users. The well-defined API and standard protocols used make his life easier. As a result, the users will be able to use the well-know university media portal and get much better selection of contents from various providers. |
| Elen | Elen - Media services manager at Cheep University Adam is responsible for media services at his university but they have no content repository services available. Due to budget constrains, he uses YouTube for Education to store various lecture and VC recordings in the cloud. He created a dedicated YouTube channel for his university and linked other related YouTube channels to it that he found appropriate. Although most of the students are familiar with YouTube, Adam is not really satisfied by the search functionality, the lack of metadata that YouTube allows him to manage, and the fact that various commercials and irrelevant search results may pop up. Adam heard about the TERENA OER portal front-end that was tailored to multimedia content representation and found it as a much "cleaner" and streamlined solution to be provided to his users. However, Adam doesn't want to loose or migrate any of the content that he already uploaded to his YouTube channel. Luckily, the TERENA OER aggregation engine is able to harvest metadata from YouTube (among others) and present the search results in the OER portal. Adam is now happy with the new TERENA OER portal front-end and his users can actually access the very same content from YouTube as well as all the other relevant content from non-cloud based local repositories that YouTube would never be able to reference to. |
1st meeting
Attendees: Eli, Vicente, Giannis, Rui, Jack, Peter
Agenda:
- What are the SMART goals of the pilot
- How we are going to deliver the pilot
Recording:
http://emeeting.campusdomar.es/recording/838013fa539370e4d9a7d3cd3fd55361
Notes:
Virtual meetings will be held bi-weekly for the pilot participants. The delivery of the contracted tasks should be monitored more closely and frequently (at least weekly) by the person responsible for the delivery.
There was a discussion whether the 9-month pilot period is okay or too short. It basically depends on the detailed objectives (SMART goals) that we want to achieve.
The identification of the target user groups and the engagement with the professors are essential. Portal features like access to thumbnails, embedded rich media players, see what other people use, etc. are important for them.
The only demonstrator of the OER harvesting engine back-end is the portal front-end. We need to define the most important features of the portal.
An agile approach must be taken where we define some personas (user stories) first, mock-up a couple of portal examples, and define the back-end requirements to that.
Users => Portal features => Metadata schema and information model => Aggregation engine
The processing and validation of the collections (connected repositories) takes time. We also need some kind of filtering of the good quality metadata.
Moodle LMS widgets should also be incorporated into the pilot system.
The next coming meetings should focus on only one topic at a time to reduce discussion time. (Personas will be discussed next time).
Key Performance Indicators for the TERENA OER pilot's outcome.
| Component | Expected outcome |
|---|---|
| TERENA OER portal |
|
| Metadata aggregation |
|
Indicator name | Expected progress |
|---|---|
Number OER content providers to be invited | 15 |
Number of content providers that will share their OER through TERENA OER | 5 |
Number of OERs shared through the OER TERENA portal | 10.000 |
Connection with global OER initiatives e.g. GLOBE | 1 |
Number of languages supported at the TERENA OER portal | 2 (EN and ES) |
Number of defined metadata compliance levels | 3 (Mandatory, Recommended, Optional) |
Dissemination activities (Presentations and publications) | 3 |