Attendees: Vicente, Eli, Giannis, Kostas, Nelson, Adam, Tibor, Antonio, Jean-Francois, Sigita, Peter Notes by Sigita Presentations Links and AttachementsAttachments 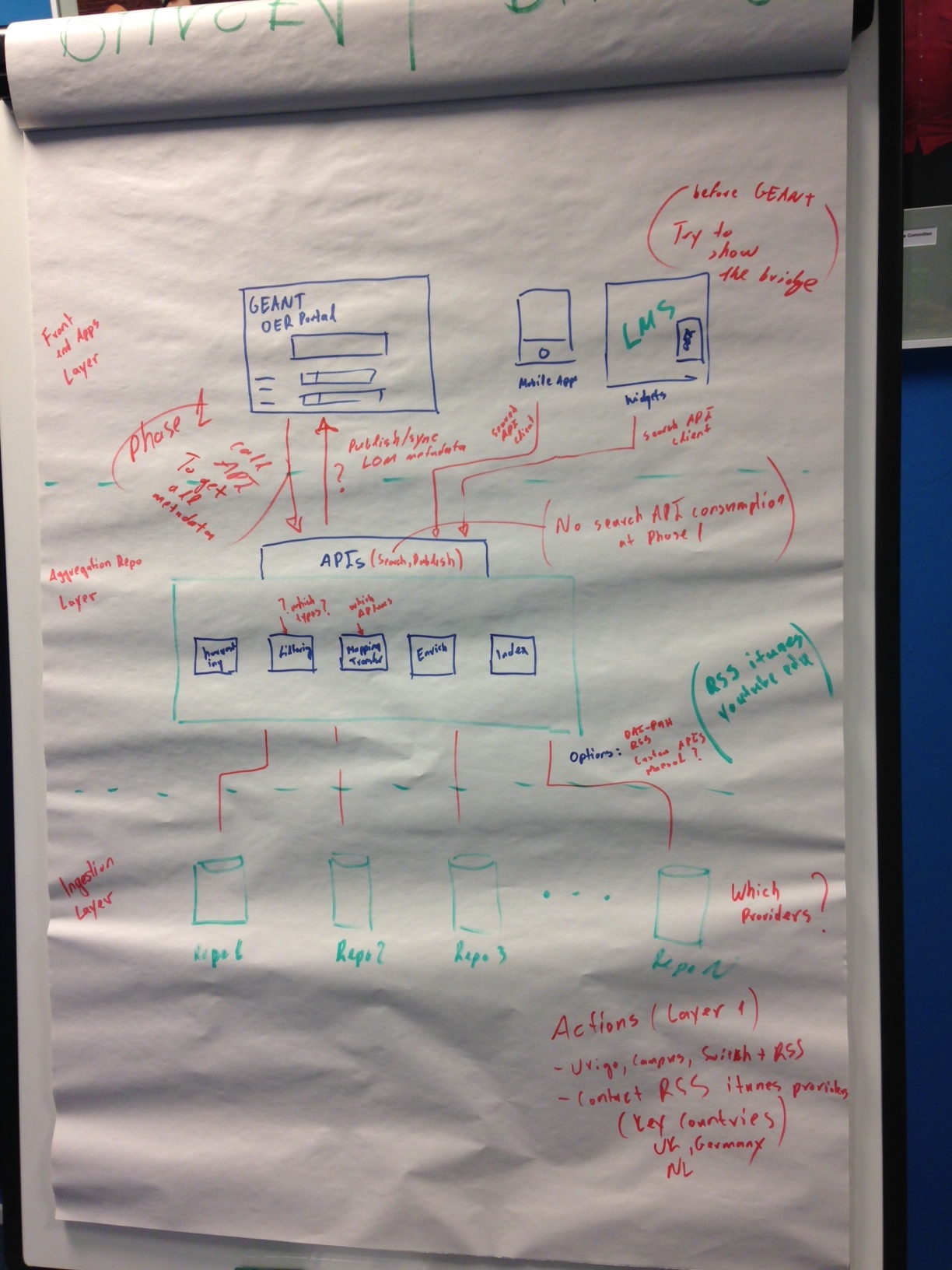
*AGREEMENTS*
0) Project phases:
- Phase 1 (Version 1.0) - until December 2014 (TERENA pilot funding)
- Phase 2 (Version 1.1) - Jan 2015 - April 2015 (no extra funding)
- Phase 3 (Version 2.0) - April 2015 - May 2016 (GN4 T3 Phase 1 funding)
2) The primary focus is on higher education and research (HEI&R) content repositories managed by an NREN or connected institutes.
3) The media type is "multimedia" (lecture recordings, conference recordings, learning objects) that includes video, audio, animation and recorded content stream but excludes still pictures and/or documents in Phase 1.
4) Two usage scenarios:
a) User starts searching globally using Google search service.
- GÉANT OER web portal indexes meta-data so Google finds it.
- User goes to GÉANT OER portal from Google and continue/refine searching there. *ADDED VALUE*
- When the users finds the content, goes off to the local repository or use the embeded player if available (learning process starts).
b) User starts searching in the local/institutional repository.
- Unsatisfied by the results but there is a GÉANT OER search widget made available by the local portal (?) *ADDED VALUE*
- User searches in the widget that directs to the GÉANT OER portal.
- As soon as the content is found and the learning process starts, user goes off to the content repository or use the embeded player if available.
5) Portal features and functionalities in Phase 1:
- Display thumbnails of multimedia objects (i.e. video, audio, animations, but no still pictures or images)
- Include direct URL to the object where available. Use embedded player or naked player provided by the source repository where possible.
- Display metadata based on the application profile (mandatory/recommended/optional) agreed by the pilot group.
- Handle Creative Common licensing.
- Facilitate browsing and faceted search (i.e. organised in predefined categories based on closed vocabulary e.g., UNESCO subjects)
- Implement simple and advanced search; either based on the back-end engine search functions or the Google search engine restricted to the portal. Develop a roadmap for the advanced search functions and the pilot service evolves.
- Implement sharing, primarily via e-mail and social media platforms.
- Apply responsive web design for proper scaling and rendering on mobile devices.
- Deal with user registration; only LDAP-based local registration in the first phase but be ready for Single Sign On (e.g., social media login) and access federations with eduGAIN.
- The portal interface language shall be English; the metadata language should be English if available or the original language of the content.
- Include information pages such as: About us, Help, Contact, Terms & Policies, Disclaimer.
6) Portal features and functionalities in later phases (TBD):
- Federated access and membership management.
- Multi-lingual user interface and customization option.
- Web access for disabled.
- Paradata collection and handling including: rating, commenting, popular items, suggested items, dynamic tag cloud, usage information, quality issues.
- Peer review functionality.
7) List of good quality repositories to start with:
http://tv.uvigo.es/
http://tv.campusdomar.es/
https://educast.fccn.pt/
https://cast.switch.ch/
University of Manchester
iTunesU RSS targets...
YouTube channels...
8) Metadata application profile need to be finalised and provided to the connected repositories to comply with. This could be a mix of IEEE LOM and DublinCore. Keywords are not mandatory. We need help from the providers to translate their metadata schema/vocabulary properly.
*ACTIONS*
I) On Giannis to finalize the metadata application profile. This should be a clear recommendation to the connected repositories.
II) On Kostas to investigate iTunesU RSS harvesting as well as YouTube channel harvesting.
III) On Vicente to start developing the web front-end portal based on the agreed feature set above.
IV) On Nelson to work out a provocative promotion campaign for institutional repositories saying: "Are you ready for Open Education?", "Are you ready to publish your content with open licences?", "Are you ready to connect to the GÉANT OER?"
V) On Peter to finalise and administrative and contractual details.
VI) On ALL to contact your friendly institutes and ask for the iTunesU RSS feeds (if not the OAI-PMH target to their repository). At least, one university per country represented in the OER pilot Pass it on to Kostas.
*NEXT MEETING*
I think, we need an on-line meeting in two weeks to speed up the process as now we have a good understanding and consensus. I'll circulate a Doodle poll soon. Notes from Giannis (GRNET) Outcomes of the discussions - TERENA will join Dante http://www.geant.org/Pages/Home.aspx
- We can have a small delay until March because the geant 4 will start on 1/4/2015
- Rename to Geant OER pilot
- We need to have federated identity for all the researchers and teachers to ensure the SSO
- For the first we could have SSO with google but for the next phase an approach based on AAI
- We could have a bridge for the moodle at the level of pymukit
- For the type of content that we will have: video, audio, moving pictures, but not still images
- Mooc builder and lms are potential customer and not the providers
- Searching inside the video should be in the future phase. We need to include a manifest element in the data model and this requires significant extra effort
- We could try to extract the duration automatically from the data provider but this could be very time consuming. Check if duration is provided in itunes data model.
- UGC not on the portal but through a separate repository tool
- Categories as they are in the uvigo TV
- For the subject we agreed to use the UNESCO classification
- Google custom search is very good way to attract people from Google because it is indexed directly the metadata.
- We need to make the metadata to be indexed quickly by google
- Contact Uvigo to decide if thumbnails will be generated at the portal
- Add embed functionality
- User interface in English. For the metadata English if available and show other lang else
- Symposium of grant plus in Athens on February
- Easy2rec a tool for the teacher generated content
- An interesting tool for connecting pymukit with opened moocv platform
- A nice idea of using iTunes RSS
- We can harvest content from YouTube edu
- Content providers: Start only with uvigo, campus do mar, maor and switch. Extend to other through iTunes rss. Select the key
- Show on the portal only recommended and mandatory metadata elements
- Moodle module based on pymukit
GRNET actions
- Disable the old solr API that we have - Kostas
- agree on the new sync API between aggregation engine and portal - Kostas and Uvigo tech team
- Check the switch repository has implemented the new OAI target.
- Check if the subject is present in uvigo OAI target. If not ask Vicente to add it - Kostas
- Contact Uvigo to decide if thumbnails will be generated at the portal - Kostas
- Next Steps for the aggregation engine
- Finalize the new schema - Kostas and Giannis
- XSD - Kostas
- Extend RSS - Kostas
- Harvest - Kostas
- Provide the XML or json files - Kostas and Uvigo
|