...
- OER data issues by Vicente https://docs.google.com/document/d/1GXTaY1g-hLB_ySXC9sMwHruwzEhYfR5x88fquFuvy-c/edit?pli=1
- Fixes by Kostas:
- Improved the mappings from native RSS Itunes U metadata and DC to the LOM based OER Application Profile.
- Extended the RSS Harvester to gather information from RSS Channel element and inject it to each and every element where the specific info is missing for example the itunes:image.
- Extended the seach API to offer duration, format and contributors name.
- The elements' possible detected languages are limited to en and es.
- The dates issue is not addressed(and it will be very difficult to be addressed since there is a great diversity in the way dates are defined)
- A new repository(Standford) is added.Peter sent it to me before sometime ago.It is RSS Itunes U based.Check the dashboards for more info.
...
| Anchor | ||||
|---|---|---|---|---|
|
...
| Note | ||
|---|---|---|
| ||
Participating: Peter, Kostas,Vicente, Eduardo, Giannis, Eli
Agenda: 1. Summary/Update - Current Status 2. Focus on the Content, Functionality 3. Update on the back-end engine 4. Front and back end interaction 5. Timeline
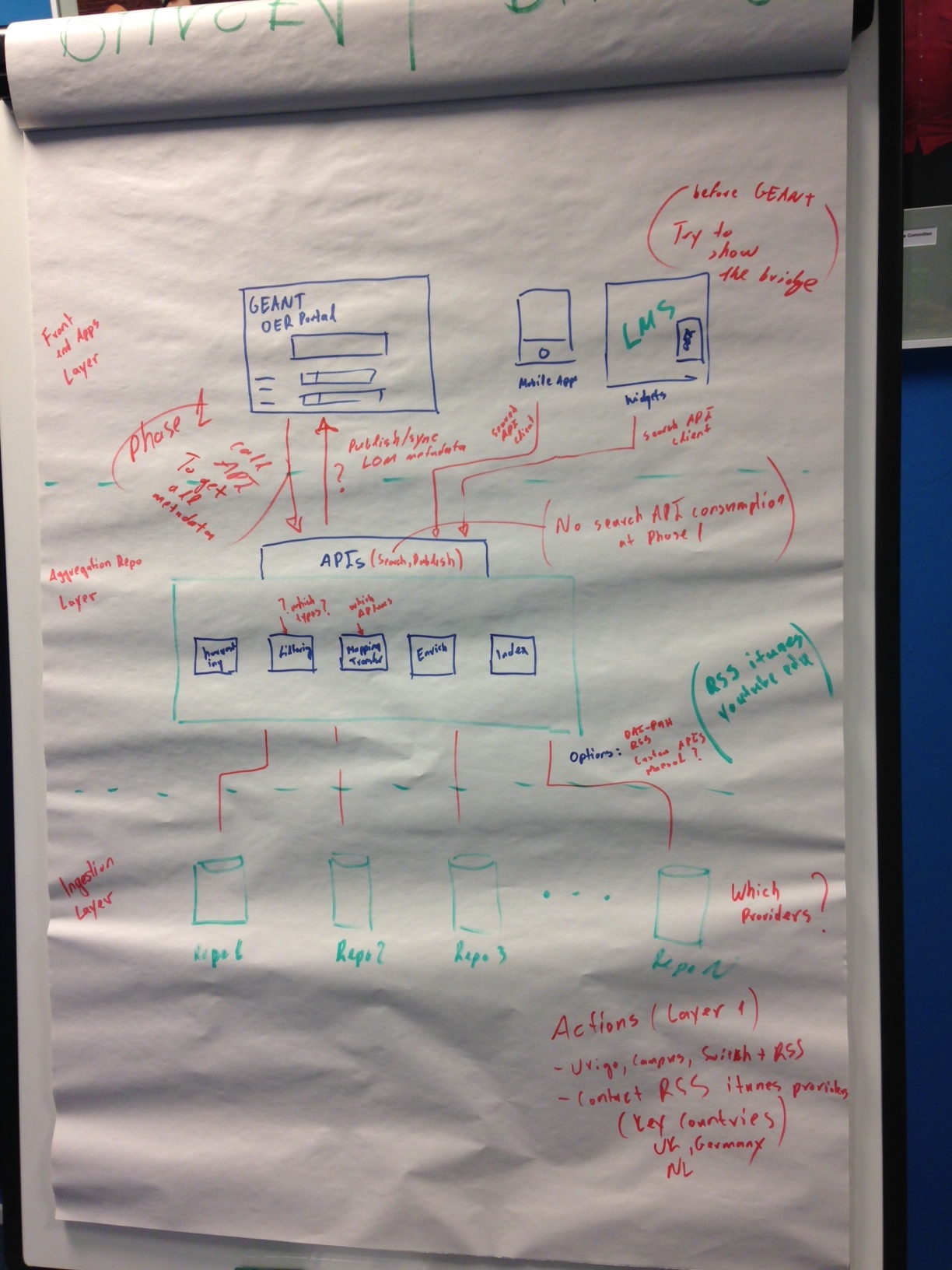
- - - 1. Current Status Vicente: working mainly on data structure, adapting the PUMUKIT structure to the application profile working on the import scripts - not as straightforward as expected; modifying the scripts all the time - related to the structure and the vocabulary [demonstrates JSON file example: issues with specific fields, supposed values, file formats do not match - need a translation at an aggregation level, media format doesn’t appear, strange language codes - or appear to be English, but isn’t - language codes should be translated, lack of numeric codes, etc.] - issued needed to be solved in order to get good data Peter: problems related to the metadata translation - should be translated into one format or schema Vicente: some issued should be fixed at the repository level Peter: proper translation needed, metadata not exposed by local repositories - a) ask them to change that, b) try to translate it automatically will have to tackle that later on Vicente: our own repositories - improving the data exposed in order to make it easy to harvest, but data coming from iTunesu - cannot count on cooperation with the data provider; translation should be done at the repository level we have all the tools, just need to focus on improving the harvesting process Peter: can compare the local repository and the one harvested - enough for us to prove that it will work Kostas: the phase of transformation is problematic, we don’t know what are the elements used from others’ perspective, might have problems with mapping the local elements with the elements of TERENA OER Peter: thumbnail gets lost for example; need to look for the basic fields we agreed on Kostas: last time we were harvesting there were no thumbnails Vicente: part of the collection, not of the item, but we are not working with collections now Kostas: could harvest information where thumbnail is a part of the item Vicente: need to interact more to solve minor issues Kostas: send me the list of issues
Vicente: regarding the portal - some objects have been harvested, currently the URL exposed is not the direct URL to the media, but the player page (can be changed) categories, filters search - first implementation information available at provider level, possible to harvest it
2. Focus on Functionality Peter: functions need to work, else the end-users will leave, if something doesn’t work, should not be on the pilot version; ok to put new features in as they become functional Vicente: this is work in progress, users wont be exposed to anything that won’t be working, functionalities there for demonstration purposes only, will be removed
- - -
Peter: Kostas, once the translation is done, others will work or are there differences? Kostas: main issue is translation, has to be done together with Vicente and his team Peter: scalability of this process in the future - tedious manual approach for now for every repository; next repository will have to be treated the same? doesn’t seem scalable Kostas: difficult to create a transformation file for every provider, will take time Giannis: the first version is for the internal consumption, but later it will be important to communicate to the data providers willing to join Vicente: maybe institutions willing to do what is needed, but might not; or we can learn to harvest the apple feeds properly Peter: would not fixate too much on the apple one, we want to connect different sources Giannis: need to have some educational metadata, else we will just replicate the iTunes harvesting mechanism; need to understand the semantics of the metadata - main problem, else can be corrected
ACTION: Vicente to send a detailed list of issues to Kostas
Eli: need to see how many hours Kostas will need for every repository 5-10 hours - worth it, else need to consider
Giannis: either remove the subject from the front end, or not use metadata that has no subject element - will apply to many elements
Eli: if we will see that we need more go arounds to fix something, maybe we can discuss the technology aspects in the next phase Peter: we will have development time in the next phase (GN4, April next year) - Kostas will be spending a lot of time working on it
- - -
Timeline
Peter: one more meeting before holidays or better in January? Can also follow up individually - (will be back on 5 January)
Giannis: specific collections from the iTunes site - who is responsible for those collections? Peter: iTunesU was identified as an escape for now, but need to focus on the local repositories - (will be back on 5 January)
Giannis: specific collections from the iTunes site - who is responsible for those collections? Peter: iTunesU was identified as an escape for now, but need to focus on the local repositories - everyone in their own countries should look for it, happy to do that in the Netherlands (also need to address the language question later) Giannis: i will look for Greek collections Peter: next meeting in Januaryeveryone in their own countries should look for it, happy to do that in the Netherlands (also need to address the language question later) Giannis: i will look for Greek collections Peter: next meeting in January
Software fixes by Kostas
|
Anchor 8th 8th
| Note | ||
|---|---|---|
| ||
Attendees: Vicente, Eli, Giannis, Kostas, Nelson, Adam, Tibor, Antonio, Jean-Francois, Sigita, Peter Presentations
Links and Attachments
*AGREEMENTS*
Notes from Giannis (GRNET) Outcomes of the discussions
GRNET actions
|
...