The pilot has been closed, results can be found in the Deliverables section.
Duration: March 2014 - January 2015
Budget: 43.000 EUR - Actual expenses: 39.000 EUR
COLLECTION OF FINAL DELIVERABLES (PDF)
The OER pilot service becomes part of the GN4 project SA8 activity starting in April 2015.
Contents: | Contact details: TF-Media mailing list is at <tf-media@terena.org> TERENA PDO The contact person for this activity is Peter Szegedi <szegedi@terena.org>
|
|---|

Motivations
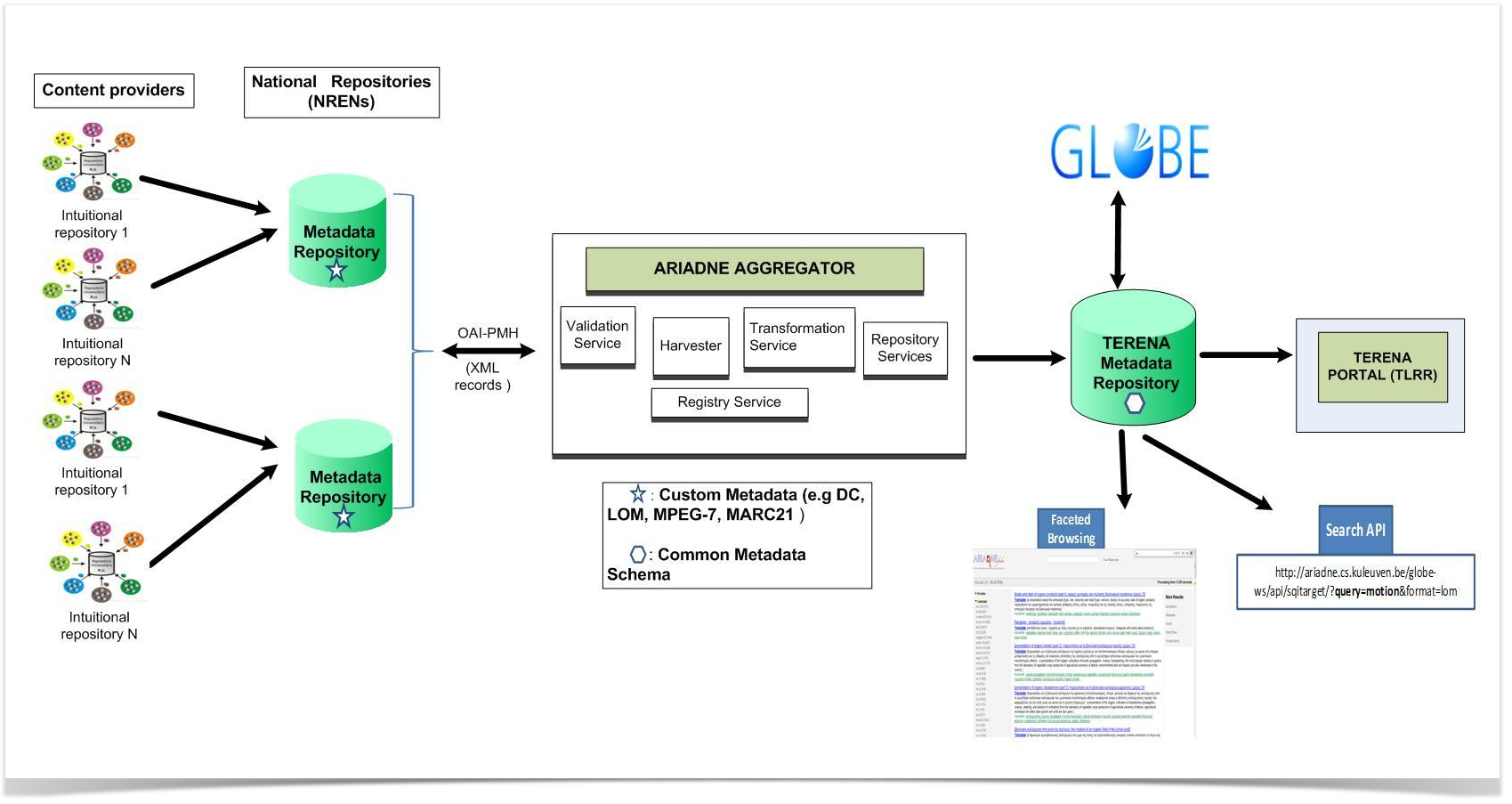
The TERENA task force TF-Media (2010-2013) concluded with a project plan to try and implement a European-level OER metadata repository service for the benefit of the Research and Education community gathered under TERENA/GÉANT. The fundamental principles of such a platform/service have been discussed and summarised by the task force.
...
The main motivation for developing a metadata repository (European-level aggregation point or referatory) and an OER portal (federated single access web front-end) service would be to support the NRENs and their stakeholders (i.e. the broader TERENA/GÉANT Research and Education Networking Community) in engaging with open education by providing value-added support services.
The OER service intends to aggregate metadata (not the content) at the European-level and helps Universities and NRENs stepping to the next level (reach the critical mass e.g., in terms of the number of objects) towards exposing their OER to global repositories (such as GLOBE [9], for instance).
Aim of the pilot
The primary aim of the TERENA OER small project is to develop the first working prototype of the OER service (including the metadata aggregation engine and the web portal front-end) and pilot a service for the broader TERENA/GÉANT Research and Education Networking Community in 2014. The pilot service can then be taken over by the GN4 project for further technical enhancement and service development aiming to roll out in production.
The TERENA OER small project is to bridge the gap between the end of TF-Media (nowfinished on Dec 31, 2013) and the beginning of GN4 (April 2015). The reason why the idea must be tested in a TERENA small project before it’s introduced in GÉANT is the fact that the critical mass (in terms of participants, support, interest, etc.) has to be gained before any sustainable service development can be done. OER seems to be a typical “chicken-n-egg” problem at the moment (i.e. without a working prototype it’s hard to gain significant interest and without significant interest it’s hard to convince the development) therefore, the TERENA OER small project has to take this initiative. The OER is not the service that the NREN community is desperate to build (e.g., like the Trusted Cloud Drive pilot was in 2012) but it’s something that TERENA the lead has to take the lead be taken on (e.g., like the NRENum.net service pilot was in 2008) in order to facilitate the development of future value-added services on top (including MOOCs and others).
| Anchor | ||||
|---|---|---|---|---|
|
The TERENA OER small project can be delivered in four tasks over 9 months (relaxed timeline):
...
More information is available in the pilot project description.
Deliverables
Documentation
First first DRAFTs:
- OER-Initial-Study-DRAFT-v1-IUCC.pdf
- OER-Initial-Study-Architecture-v1-GRNET.pdf
- OER-PR-plan-v1-FCT.pdf
...
- Aggregation engine statistics:
- Here you can find the aggregation workflow results visualized.
- Here you can find the statistical analysis results based on the final aggregated metadata.
- Here you can find the Rest API service offered by the repository.The Terena OER Portal could use it in order to visualize its results.
- Here you can find a simple web based client which sits on top of the API mentioned above.
Second DRAFTs:
- OER-Initial-Study-DRAFT-v2-IUCC.pdf
- OER-Initial-Study-Architecture-v2-GRNET.pdf
- TERENA-OER-AP-draft.pdf
- Aggregation engine oai-pmh target:
- Source for other harvesters here.
- Aggergation workflow for Content Providers http://terenaoer.grnet.gr:8082/doku.php
Additional documentation:
- OER data issues by Vicente https://docs.google.com/document/d/1GXTaY1g-hLB_ySXC9sMwHruwzEhYfR5x88fquFuvy-c/edit?pli=1
Back-end engine statistics
- http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Aggregation
- http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Metadata%20Analysis
- http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/ES_Access_Stats : grnet/grnet
Fronf-end portal (demonstrator)
...
| Anchor | ||||
|---|---|---|---|---|
|
1st meeting - 28 March 2014 @ 10.00 CET
2nd meeting - 2 April 2014 @ 10.00 CEST
3rd meeting - 12 May 2014 @ 14.00 CEST
4th meeting - 15 May 2014 @ 11.00 CEST
5th meeting - 30 June 2014 @ 13.00 CEST
6th meeting - 26 Augustus 2014 @ 16.00 CEST
7th meeting - 16 September 2014 @16.00 CEST
8th meeting - 9 October 2014 @ 9.00-17.00 CEST (Face to face meeting in Amsterdam, Netherlands)
9th meeting - 4 December 2014 @ 14.00 CET
10th meeting - 19 January 2014 @11.00 CET
11th meeting - 28 January 2014 @10.00 CET (Pilot has been CLOSED)
| Anchor | ||||
|---|---|---|---|---|
|
| Note | ||
|---|---|---|
| ||
Participants: Eli, Vicente, Kostas, Adam, Peter Notes 1) Kostas showed the statisitcal interface of the back-end.
2) Vicente showed the front-endportal.
Adam explained the vocabulary that Videotorim use for the subject element: http://videotorium.hu/en/categories
3) Peter elaborated on the next steps
Everyones' efforts and hard work are very much appreciated! |
| Anchor | ||||
|---|---|---|---|---|
|
| Note | ||
|---|---|---|
| ||
Recording: Notes: As we commented during the last meeting (19th Jan) I consider the development of Geant-OER Portal done. We are currently doing tests and QA on it. Any help testing the portal and trying to find bugs is very welcome. You will find it here: Please, try it and send any bug reports to this list. Open Issues:
Comments from Giannis:
Promotion examples from Nelson I’m sending this email with some of the communication examples you asked me to create during the last year. You can see attached 3 different posters in A4 format that can be used to promote the service around the world, mainly to our main target, the NREN’s. 3 Key Messages: 1- Are you ready for open education? 2- Are you ready to connect to the Géant OER? 3- Are you ready to publish your content with open licenses?
These examples can be easily promoted by email, newsletters or as a printed version in conferences and institutional events. I think it would be important to create a strong corporate identity (name, logo, slogan), before the project release as I wrote in the communication proposal. In my point of view these elements will be the key to promote the service and to engage users with our brand(Géant OER). I think they should be created and included in the different promotional channels since the beginning of communication process. A4_Are_you_ready_for_open_education.pdf A4_Are_you_ready_to_connect_to_the_Géant_OER.pdf A4_Are_you_ready_to_connect_to_the_Géant_OER.pdf
|
| Anchor | ||||
|---|---|---|---|---|
|
| Note | ||
|---|---|---|
| ||
Participating: Peter, Kostas,Vicente, Eduardo, Giannis, Eli
Agenda: 1. Summary/Update - Current Status 2. Focus on the Content, Functionality 3. Update on the back-end engine 4. Front and back end interaction 5. Timeline
- - - 1. Current Status Vicente: working mainly on data structure, adapting the PUMUKIT structure to the application profile working on the import scripts - not as straightforward as expected; modifying the scripts all the time - related to the structure and the vocabulary [demonstrates JSON file example: issues with specific fields, supposed values, file formats do not match - need a translation at an aggregation level, media format doesn’t appear, strange language codes - or appear to be English, but isn’t - language codes should be translated, lack of numeric codes, etc.] - issued needed to be solved in order to get good data Peter: problems related to the metadata translation - should be translated into one format or schema Vicente: some issued should be fixed at the repository level Peter: proper translation needed, metadata not exposed by local repositories - a) ask them to change that, b) try to translate it automatically will have to tackle that later on Vicente: our own repositories - improving the data exposed in order to make it easy to harvest, but data coming from iTunesu - cannot count on cooperation with the data provider; translation should be done at the repository level we have all the tools, just need to focus on improving the harvesting process Peter: can compare the local repository and the one harvested - enough for us to prove that it will work Kostas: the phase of transformation is problematic, we don’t know what are the elements used from others’ perspective, might have problems with mapping the local elements with the elements of TERENA OER Peter: thumbnail gets lost for example; need to look for the basic fields we agreed on Kostas: last time we were harvesting there were no thumbnails Vicente: part of the collection, not of the item, but we are not working with collections now Kostas: could harvest information where thumbnail is a part of the item Vicente: need to interact more to solve minor issues Kostas: send me the list of issues
Vicente: regarding the portal - some objects have been harvested, currently the URL exposed is not the direct URL to the media, but the player page (can be changed) categories, filters search - first implementation information available at provider level, possible to harvest it
2. Focus on Functionality Peter: functions need to work, else the end-users will leave, if something doesn’t work, should not be on the pilot version; ok to put new features in as they become functional Vicente: this is work in progress, users wont be exposed to anything that won’t be working, functionalities there for demonstration purposes only, will be removed
- - -
Peter: Kostas, once the translation is done, others will work or are there differences? Kostas: main issue is translation, has to be done together with Vicente and his team Peter: scalability of this process in the future - tedious manual approach for now for every repository; next repository will have to be treated the same? doesn’t seem scalable Kostas: difficult to create a transformation file for every provider, will take time Giannis: the first version is for the internal consumption, but later it will be important to communicate to the data providers willing to join Vicente: maybe institutions willing to do what is needed, but might not; or we can learn to harvest the apple feeds properly Peter: would not fixate too much on the apple one, we want to connect different sources Giannis: need to have some educational metadata, else we will just replicate the iTunes harvesting mechanism; need to understand the semantics of the metadata - main problem, else can be corrected
ACTION: Vicente to send a detailed list of issues to Kostas
Eli: need to see how many hours Kostas will need for every repository 5-10 hours - worth it, else need to consider
Giannis: either remove the subject from the front end, or not use metadata that has no subject element - will apply to many elements
Eli: if we will see that we need more go arounds to fix something, maybe we can discuss the technology aspects in the next phase Peter: we will have development time in the next phase (GN4, April next year) - Kostas will be spending a lot of time working on it
- - -
Timeline
Peter: one more meeting before holidays or better in January? Can also follow up individually - (will be back on 5 January)
Giannis: specific collections from the iTunes site - who is responsible for those collections? Peter: iTunesU was identified as an escape for now, but need to focus on the local repositories - everyone in their own countries should look for it, happy to do that in the Netherlands (also need to address the language question later) Giannis: i will look for Greek collections Peter: next meeting in January
Software fixes by Kostas
|
Anchor 8th 8th
| Note | ||
|---|---|---|
| ||
Attendees: Vicente, Eli, Giannis, Kostas, Nelson, Adam, Tibor, Antonio, Jean-Francois, Sigita, Peter Presentations
Links and Attachments
*AGREEMENTS*
Notes from Giannis (GRNET) Outcomes of the discussions
GRNET actions
|
Anchor 7th 7th
| Note | ||
|---|---|---|
| ||
Attendees: Adam, Vicente, Eli, Peter, Sigita, Kostas, Giannis, Nelson Recordings: http://emeeting.campusdomar.es/recording/a18776711ec9a1ba563a68ecde656eef Minutes: 1) Status of the initial study, comments by GRNET, Wiki content, etc. V: the two documents are mainly definition of the service - lacks info what the system will look like and what features will it provide P: you don’t font the info needed for development? - clear concrete feature list to be determined during the face-to-face meeting E: the players of the project will be clearly explained in the next version of the document (to be produced in a few days) - looking for input, comments V: used to working on user driven basis - need to understand what the users are expecting; need to check user specifications (not to be fulfilled at first, but need to make sure that the architecture is ready to be updated for the later versions) K: […?] P: Kostas already working on aggregation of the metadata, had a look at the status and statistics - must be part of the document (screenshots, etc.) - to understand what features can be/cannot be implemented; architecture has to be flexible for when we are ready to implement more P: metadata - a must, paradata - might be left for a later stage K: issues with getting repositories to expose their paradata G: the only source of paradata - OER portal - maybe more in the future (if we want paradata, this has to be collected through the portal) V: the system currently only collects statistics, but ratings are easy to add G: better to have the users express this kind of requirement
G:should professors be the primary persona? maybe would be good to have one primary focus. P: two groups - end users and system admins, would not split those groups further E: risky to use interviews with professors - can focus on very narrow solutions, need large scale interviews, need to understand what is the state of the art in the world, find more common, most relevant features V: in any case, need to be connected to the prospective end-users - maybe a more complete survey is needed? P: continuous feedback necessary G: 20-30 interviews needed, but due to time limitations a prototype is needed - create the first version and then ask the users for feedback
G: made a new version of the study, no major changes only improvements and small additions E: integrated most of the comments, got comments from more professionals (mainly professors) - new version will be circulated within 10 days from now
ACTION: Giannis will send his updated version, Elis will prepare a draft for the face-to-face meeting
2) Web front-end development P: work for Vicente’s team will be defined during the face-to-face meeting V: need a definition asap - features and structure; also need a contract asap to define man power P: will start an e-mail dialogue with Giannis and others to give you more clarity before the face-to-face meeting and also start working on the paper work (contracts) now E: study document contains quite some information about the features etc. that can be used
P: the first version of this application profile should come from Giannis and Kostas G: we can provide first proposal for that, but its an exercise based on the real needs of the users V: use the user stories for the exercise P: plus personas described on the wiki
3) Face to face meeting preparation P: will prepare an agenda, full day meeting (9:00-17:00), send your arrival times, dinner possible the day before; will need to make decisions during this meeting, so good agenda and good preparation is crucial; booking hotels might be difficult - will prepare some recommendations
4) GN4 Task 3 update 5) Position paper of NRENs on Open Education
6) Priorities, deadlines, AoB G: Application profile deadline - before the face-to-face meeting? P: definitely - need to have the new versions of the study from everyone, will try to incorporate work from the wiki, and the application profile; will come up with a draft agenda as well and send it out for comments V: comments for the user stories are welcome - can be found on google.docs |
1st meeting - 28 March 2014 @ 10.00 CET
2nd meeting - 2 April 2014 @ 10.00 CEST
3rd meeting - 12 May 2014 @ 14.00 CEST
4th meeting - 15 May 2014 @ 11.00 CEST
5th meeting - 30 June 2014 @ 13.00 CEST
6th meeting - 26 Augustus 2014 @ 16.00 CEST
Next coming:
in two weeks
Face to face meeting TBC in Amsterdam, Netherlands
...
Anchor 6th 6th
| Note | ||
|---|---|---|
| ||
Attendees: Eli, Giannis, Kostas, Nelson, Peter, SygitaSigita Agenda: 1) Contributions from IUCC and GRNET (Eli and Giannis) 2) Face to face meeting (Peter) 3) Aggregation engine update (Kostas) 4) GN4 SA8 propoal (Peter) 5) AoB
Minutes: 1) Contributions from IUCC and GRNET (Eli and Giannis)
Peter: happy with the content of the first draft - should be merged together to have one overview on the pilot
Eli: What we have in our doc now (welcomes feedback):
1. Metadata (what kind is needed, based on TERENA survey?) 2. Paradata (comments, user ratings, tags, etc.) 3. Connectivity (connected to libraries, other depositories outside of the main project) 4. Community (social media, creation of the community) Some of this will be done in the first phase, some in the second. Wide project, narrow core - unique project, dealing with a lot of issues on the European level Will be able to connect with many organisations outside of the core of this project Survey - very important, could be added as an annex or otherwise integrate. Document also sent to some OER experts
Peter: How can this be merged with the GRNET contribution?
Giannis: Comments on IUCC document: Good basis Would be good to provide the scope at the beginning of this merged document 3 main objectives:
For specifications: user stories, personas, mockups -> done already, so can easily be included Q: mandatory subject element - proposed or strongly recommended? we don’t have the subject element in many cases
Eli: all the second part of the doc is opened to discussion, mainly the metadata; some based on the survey; metadata field taken from one of the documents discussed in the past, but it has to be edited together need to understand the scale of the project and other relevant details Survey and previous discussion can/should be added to the document
Giannis: agree that it could be an appendix together with other long tables Q: Nothing mentioned about vocabularies?
Eli: if we use the (LOM?) then cannot use anything other this is something that needs to be discussed knows a specialist that can help
Giannis: should include a section about this in the document include some options that we have this part can be connected to the user stories and search and browser functionalities
Eli: vocabulary is relevant to how you add the materials to the system - technology issue, how to implement it, and the filters - might be the best if we can have as many as we can filters and vocabulary
Giannis: also the need to define mappings and to make transformations - need to decide whether it will be done automatically or manually - if manually someone has to take over this task
Eli: how many layers? 2 or 3? effective for the users
Giannis: this can simplify the work but the work of transportation will still be needed this has to be foreseen for the future
Peter: this issue can be left for the face to face meeting - agreement on this is needed
Giannis: we need to define the reference classification at this stage - for as many layers as needed
Peter: maybe skip for phase one, introduce later
Giannis: educational levels - could we also target vocational education?
Eli: should be open to everybody so we can say “higher education and any other users”
Peter: we narrowed down the scope - education in general, focused on higher education (primary focus of most of the NRENs), and focus on those, where the NRENs are active in - could be extended as a next step
Giannis: target audience - does not come up in the proposed schema
Elis: target audience is important to users in the higher education and outside; open to discussion and we have to see what you can implement having a target audience filter is important in the end of the process we might understand that there is no need for this we can take it out, but i believe that it is needed can be mandatory, optional or recommended Kostas: difference between location element and url element?
Eli: sometimes there is a difference [explains] - [url issue and other should be part of the face to face meeting]
Giannis: two cases - page where resources shown and where resource can be accessed at
Eli: has doubt about the LOM is it would be used, but those who will do the implementation should be part of the face to face meeting; need to agree on the mandatory
Giannis: maybe include a section with other options to LOM?
Kostas: Keeping the balance on the mandatory elements - nice to have as many elements as we need, but from aggregation side is makes it very strict, a lot of metadata will be dropped out, need to find a balance
Giannis: we will not be able to have more than 5-10 elements as mandatory
Eli: if we are leading the way, we need to make a standard; this needs to be discussed based on what the user will get - problem with global - almost no metadata and too much unnecessary material TERENA should recommend the standards at first maybe 5-10 mandatory fields, but recommend to have more
Giannis: agreed, but need to keep the balance
Giannis: what are the dates of the phase 1&2?
Peter: TERENA pilot - phase one is the one we can implement, the rest will be the “afterlife” of the pilot, in GN4
2) Face to face meeting (Peter) Peter: need a date Nelson: who will pay for this? Peter: preferably your org pays, but could be covered by TERENA (limited number of trips) Option 1: 25-26 September Option 2: after 7 October Will set up a doodle.
3) Aggregation engine update (Kostas)
http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Aggregation http://terenaoer.grnet.gr/index.html#/dashboard/elasticsearch/Terena%20Metadata%20Analysis 4) GN4 SA8 propoal (Peter)
There are three tasks:
Task 3 is to take over the TERENA OER pilot results in April and develop that furter toward a production service of GÉANT. Kostas (GRNET) will be the task leader of that. 5) AoB Nelson produced a DRAFT plan for the promotioal activity of TERENA OER. The document will be circulated for further comments. Peter noted that the pr and marketing efforts must be aligned and incuded in the pilot early on. Nelson's contribution is very much appreciated and will be part of the initial study. |
...