Contents:
| Contact details: TF-Media mailing list is at <tf-media@terena.org> TERENA PDO is Peter Szegedi <szegedi@terena.org>
|
|---|
Motivations
The TERENA task force TF-Media (2010-2013) concluded with a project plan to try and implement a European-level OER metadata repository service for the benefit of the Research and Education community gathered under TERENA/GÉANT. The fundamental principles of such a platform/service have been discussed and summarised by the task force.
There is a large interest around the global education community in establishing and maintaining OER or Learning Object (LO) repositories as exemplified by the number of existing repositories (e.g., MERLOT [2], MAOR [3], OER commons [4], Learning Resource Exchange for Schools from European Schoolnet [5]), organizations building and sustaining them (e.g., MITOpenCourseWare [6]), contributors integrating learning objects in repositories (e.g., OpenContent [7]), and users of these learning objects (e.g., Universities, Libraries). The fundamental reasons are:
- the growing educational demands in all countries,
- the limited capacity of face to face education to fulfil the demand in a timely manner (i.e. emerging MOOCs),
- the effort and cost involved to build multimedia learning materials, and the new possibilities offered by the Internet.
The main motivation for developing a metadata repository (European-level aggregation point or referatory) and an OER portal (federated single access web front-end) service would be to support the NRENs and their stakeholders (i.e. the broader TERENA/GÉANT Community) in engaging with open education by providing value-added support services.
The OER service intends to aggregate metadata (not the content) at the European-level and helps Universities and NRENs stepping to the next level (reach the critical mass e.g., in terms of the number of objects) towards exposing their OER to global repositories (such as GLOBE [9], for instance).
Aim of the pilot
The primary aim of the TERENA small project is to develop the first working prototype of the OER service (including the metadata aggregation engine and the web portal front-end) and pilot a service for the broader TERENA/GÉANT Community in 2014. The pilot service can then be taken over by the GN4 project for further technical enhancement and service development aiming to roll out in production.
The TERENA small project is to bridge the gap between the end of TF-Media (now) and the beginning of GN4 (April 2015). The reason why the idea must be tested in a TERENA small project before it’s introduced in GÉANT is the fact that the critical mass (in terms of participants, support, interest, etc.) has to be gained before any sustainable service development can be done. OER seems to be a typical “chicken-n-egg” problem at the moment (i.e. without a working prototype it’s hard to gain significant interest and without significant interest it’s hard to convince the development) therefore, the TERENA small project has to take this initiative. The OER is not the service that the NREN community is desperate to build (e.g., like the Trusted Cloud Drive pilot was in 2012) but it’s something that TERENA has to take the lead on (e.g., like the NRENum.net service pilot was in 2008) in order to facilitate the development of future value-added services on top (including MOOCs and others).
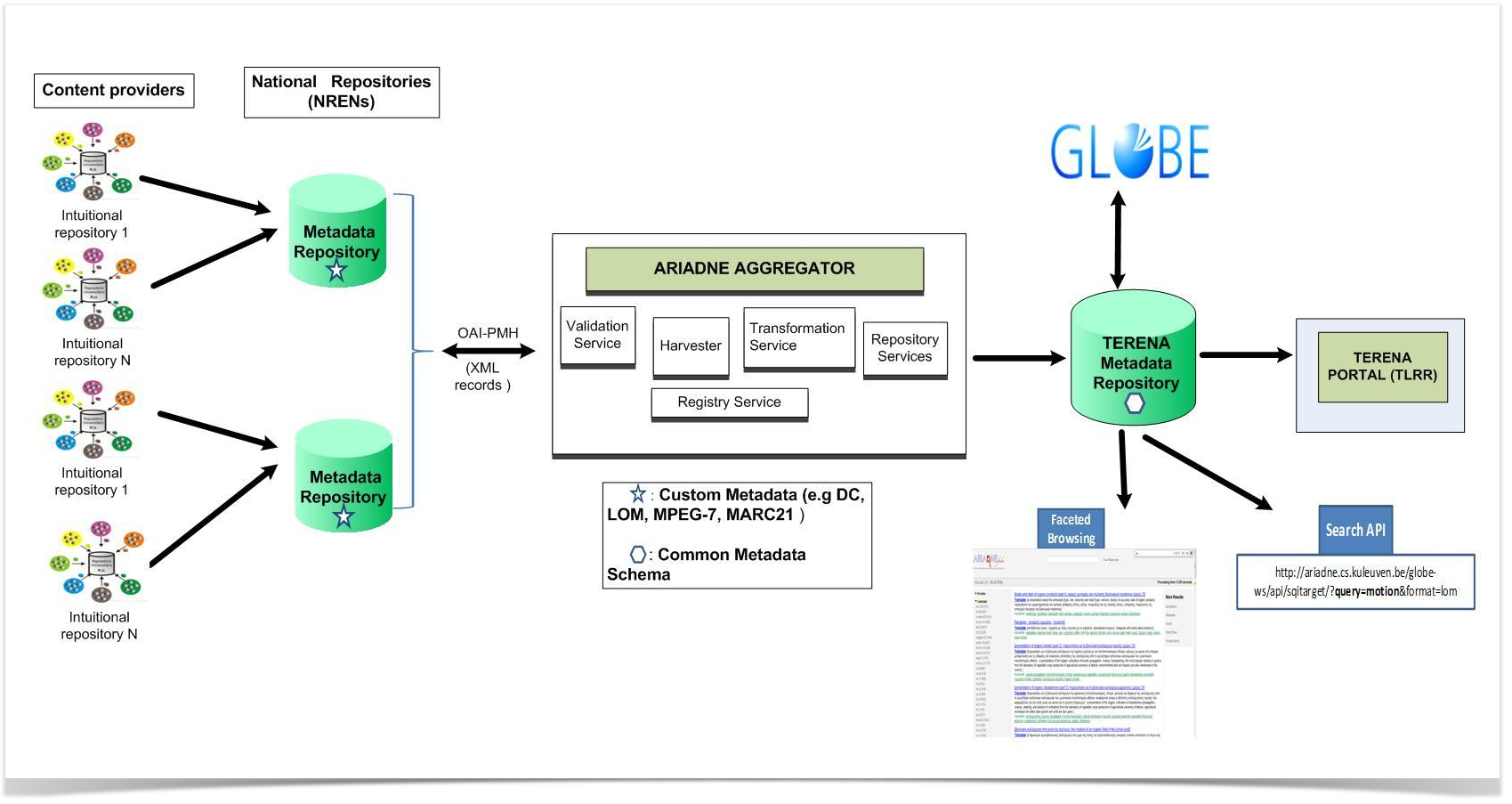
Delivering the pilot
The TERENA small project can be delivered in four tasks over 9 months (relaxed timeline):
- Definition of the minimum requirements for a common metadata schema (flexible, scalable. standard-based, etc.) taking into account the information model of the pre-selected “friendly repositories”. The potential piloting of a sample/reference repository with “good quality” metadata will also be considered by this task.
- Implementation of the ARIADNE-based metadata harvesting engine in the TERENA network.
- Development and deployment of the PuMuKit-based web portal front-end (web template).
- Integration of software components and piloting of the metadata harvesting, validating, transforming and publishing service.
More information is available in the pilot project description.
Meeting minutes
1st meeting - 28 March 2014 @ 10.00 CET
2nd meeting - 2 April 2014 @ 10.00 CET
3rd meeting - TBC
1st meeting
Attendees: Eli, Vicente, Giannis, Rui, Jack, Peter
Agenda:
- What are the SMART goals of the pilot
- How we are going to deliver the pilot
Recording:
http://emeeting.campusdomar.es/recording/838013fa539370e4d9a7d3cd3fd55361
Notes:
Virtual meetings will be held bi-weekly for the pilot participants. The delivery of the contracted tasks should be monitored more closely and frequently (at least weekly) by the person responsible for the delivery.
There was a discussion whether the 9-month pilot period is okay or too short. It basically depends on the detailed objectives (SMART goals) that we want to achieve.
The identification of the target user groups and the engagement with the professosrs are essential. Portal features like access to thumbnails, embeded rich media playrs, see what other people use, etc. are important for them.
The only demonstartor of the OER harvesting engine back-end is the portal front-end. We need to define the most important features of the portal.
An agile approach must be taken where we define some personas (user stories) first, mock-up a couple of portal examples, and define the back-end requirements to that.
Users => Portal features => Metadata schema and information model => Aggregation engine
The processing and validation of the collections (connected repositories) takes time. We also need some kind of filtering of the good quality metadata.
Moodle LMS widgets should also be incorporated into the pilot system.
The next coming meetings should focus on only one topic at a time to reduce discussion time. (Personas will be discussed next time).
KIPs
Indicator name | Expected progress |
Number OER content providers to be invited | 15 |
Number of content providers that will share their OER through TERENA OER | 5 |
Number of OERs shared through the OER TERENA portal | 10.000 |
Connection with global OER initiatives e.g. GLOBE | 1 |
Number of languages supported at the TERENA OER portal | 2 (EN and ES) |
Number of defined metadata compliance levels | 3 (Mandatory, Recommended, Optional) |
Dissemination activities (Presentations and publications) | 3 |
Component | Expected outcome |
TERENA OER portal |
|
Metadata aggregation |
|