The Task Force on Applied Media in Teaching and Learning builds on the mature relationship between NRENs and HEIs in Europe. It is established under the auspices of the TERENA Technical Programme to collect and share ideas, knowledge and experiences on how to support media applied to pedagogical (e-learning) as well as to research/scientific purposes.
Fro more information check out the TF-Media website.
Contact details: TF-Media mailing list is at <tf-media@terena.org> Task Force chair is Zenon Mousmoulas <zmousm@admin.grnet.gr> Task Force secretary is Peter Szegedi <szegedi@terena.org> |
|---|
TF-Media Open Educational Resource (metadata) portal pilot
Motivations
There is a large interest around the world in establishing and maintaining national (as well as multi-national) learning object repositories as exemplified by the number of existing repositories, organizations building and sustaining them, contributors integrating learning objects in repositories, and users of these learning objects. The fundamental reasons are: the growing educational demands in all countries, the limited capacity of face to face education to fulfill the demand in a timely manner, the effort and cost involved to build multimedia learning materials, and the new possibilities offered by the Internet.
While it is a fact that millions of materials can be found on the Internet using search engines like Google, there is no guarantee that a query will lead to trustable material on which high quality education can be built. Not to mention copyright and licensing issues. Well managed learning object repositories that aggregate high quality content offer a solution to this problem. TERENA TF-Media group focuses on multimedia learning object repositories only.
Credit: http://www.globe-info.org/
Objectives
Connecting the World and Unlocking the Deep Web - Create a one-stop-shop (broker) for national learning resource organizations, each of them managing and/or federating one or more learning object repositories within the country. TERENA OER portal initiative addresses the gap between the national repositories and the emerging global repositories (e.g., GLOBE) by establishing an European level metadata repository (i.e. aggregation point) for the national repositories acting in the R&E community. The European level repository will be a metadata repository only, the content remains in its original content repository.
TERENA is willing to make a suite of online services and tools available to its members for the exchange of learning resources' metadata, and facilitates the access to the worldwide Open Community (i.e. GLOBE) guided by the following principles:
- Keep the barrier of entry to TERENA OER low and participation high.
- Provide open specifications and community source code as much as possible, openly shared among and beyond community members.
- Use open standards, where appropriate, and contribute back to the development of these standards based on experiences and best practices.
- Respect and build on European values.
- NRENs' common face to global repositories (i.e. GLOBE)
- Operate as a community of peers.
Credit: http://www.globe-info.org/
Benefits
The expected benefits for the end-users (students and teachers) are as follows:
- More effective and motivating learning scenarios (learners & trainees).
- Better productivity and new philosophy of collaboration (authors of pedagogical material).
- Better communication and co-working schemes (researchers).
- Possible factor for harmonizing education & training policies throughout Europe.
- Spare public money by re-using open learning resources.
The pilot project milestones
- TERENA creates a European level, open source, metadata aggregation broker/portal that leaves the content (i.e. the objects) in its source domain and harvest the metadata from the national level up to the pan-European level. The portal might be hosted and operated by one or more TERENA member organizations.
- TF-Media defines the minimum requirements for a common metadata schema (e.g., 8 LOM fields) and the way how metadata can be harvested (e.g., OAI-PMH protocol)
- Start collecting metadata from the national repositories (primarily from NRENs participating in the pilot) and make them available via the TERENA portal.
- TERENA OER applies for the GLOBE membership.
- Potential service enhancements (e.g., Creative Common licensing), and value added components (e.g., integrated player, better user interface, representation of search targets).
List of interested participants
- GRNET (with Ariadne)
- IUCC (with MAOR)
- University of Vigo (with Campus do Mar project)
- ISEP (with MELOR)
- Tel Aviv University
- RedIRIS (with ARCA)
- SWITCH (with SWITCHcast)
- FCCN (with Banco do Video)
- NIIF (with Videotorium)
Q&A
Q: What can be the role of an NREN?
A: To bring the learning resources' information (metadata only, not the object itself) at the higher (i.e. European) level.
Q: Why should the national repository join TERENA OER (i.e. what is the additional value of TEREAN)?
A: To step from the national level to the pan-European and later global (i.e. via GLOBE) level of aggregation. Create the critical mass.
Q: How can I convince lecturers to share their content?
A: Tell them not to share the whole lecture but just some chunks of it as a Learning Object. In return, they will be able to re-use LOs from other lecturers to enrich their presentation.Quality assured, licensed content.
Q: What is the actual Business Case for NRENs?
A: Universities use public money to create lecture content. Sharing, enriching and re-using the content made available by lecturers eventually spares time, efforts, and public money.
Q: What is the benefit of TERENA OER over Goole Search?
A: Deep search can be done on rich metadata that can find content that is most likely hided from Google Search or other web search engines.
Related documents:
- Yves Epelboin (UPMC): Massive Open Online Courses (MOOC): An European view
- JISC Digital Repository InfoKIT http://tools.jiscinfonet.ac.uk/downloads/repositories/digital-repositories.pdf
- TERENA news item about inviting repositories to participate http://www.terena.org/news/3253/fullstory
List of related projects
Meeting minutes
- Task Force on Applied Media in Teaching and Learning (TF-Media): 25 June, 2012
- Task Force on Applied Media in Teaching and Learning (TF-Media): 21 September, 2012
- Task Force on Applied Media in Teaching and Learning (TF-Media): 22 October, 2012
- 4th technical meeting: 16 November, 2012
- Task Force on Applied Media in Teaching and Learning (TF-Media): 21 February, 2013
- 6th technical meeting: 1 March, 2013
- 7th technical meeting: 27 March, 2013
1st VC Minutes (25 June 2012)
We've just had a very productive discussion about the practical steps of the TF-Media Open Educational Resource portal pilot.
Please find the recording at http://uvigo.adobeconnect.com/p1t9d4507u8/
We've kicked off the pilot with some initial agreements however, there are still many open questions and details that need to be clarified in the near future. Stay tuned!
NOTES:
25 June 2012 @ 14.00-15.45 CET
List of participants: Andy (SWITCH), Gytis (KUT), Nikos, Giannis (GRNET); Vicente (UVigo); Eli (IUCC); Jack (TAU); Peter (TERENA)
- The importance of open sharing of educational resources was acknowledged. Many national and global initiatives were mentioned such as ARIADNE, GLOBE, MAOR, etc...
- The layered model of repositories was explained by Eli (IUCC). We (TERENA) should focus on the step between the national layer and the pan-European layer. Global peers must then be considered.
- Andy (SWITCH) noted that we should equally focus on both; how to reach out to the national community and how to aggregate at the pan-European level.
- It was agreed that the TERENA repository must be a metadata/paradata repository only. The content/object must be kept at the original location. Only the metadata of fully open materials should be harvested, in principle. The main focus is on the aggregation of audio/video content repositories in the first step (e.g., no scientific papers, publications, etc.).
- The TERENA OER portal can have enhanced, rich media search functionality (deeper than Google search) and maybe a hosted video playback option (noted by Vicente). Jack (TAU) added that maybe a content upload feature would also be an option at the aggregate layer (home for homeless concept).
- Gytis (KUT) mentioned that Creative Common licensing should be included. It was agreed that licensing is important.
- It was agreed to set up some metadata aggregating points for testing purposes:
1) Vicente (UVigo) agreed to set up a test installation of DSpace and maybe PuMuKit on top.
2) Giannis (GRNET) agreed to set up a test installation of ARIADNE tools.
3) Eli (IUCC) agreed to set up a test installation of MAOR duplicate.
- In parallel with these, an open call for content providers (i.e. NRENs/Unis with recorded lectures) will be sent out. These repositories will be connected to the three test installation above.
- See the relevant TERENA Compendium 2011 data at TER-C11-complete-web.pdf
- For the pilot, the 8 standard LOM metadata fields can be used but a common agreement on the metadata schema is needed for the long run. LOM records can be transported between systems using a variety of protocols, perhaps the most widely used being OAI-PMH.
- Peter (TERENA) will follow up with IUCC, UVigo and GRNET on the test implementations and inform the mailing list about the progress.
DRAFT
OPTION 2) In order to collect the metadata from the repositories participating in the pilot project the ARIADNE infrastructure and services (www.ariadne-eu.org/content/services) could be used.
Credit: Giannis (GRNET)
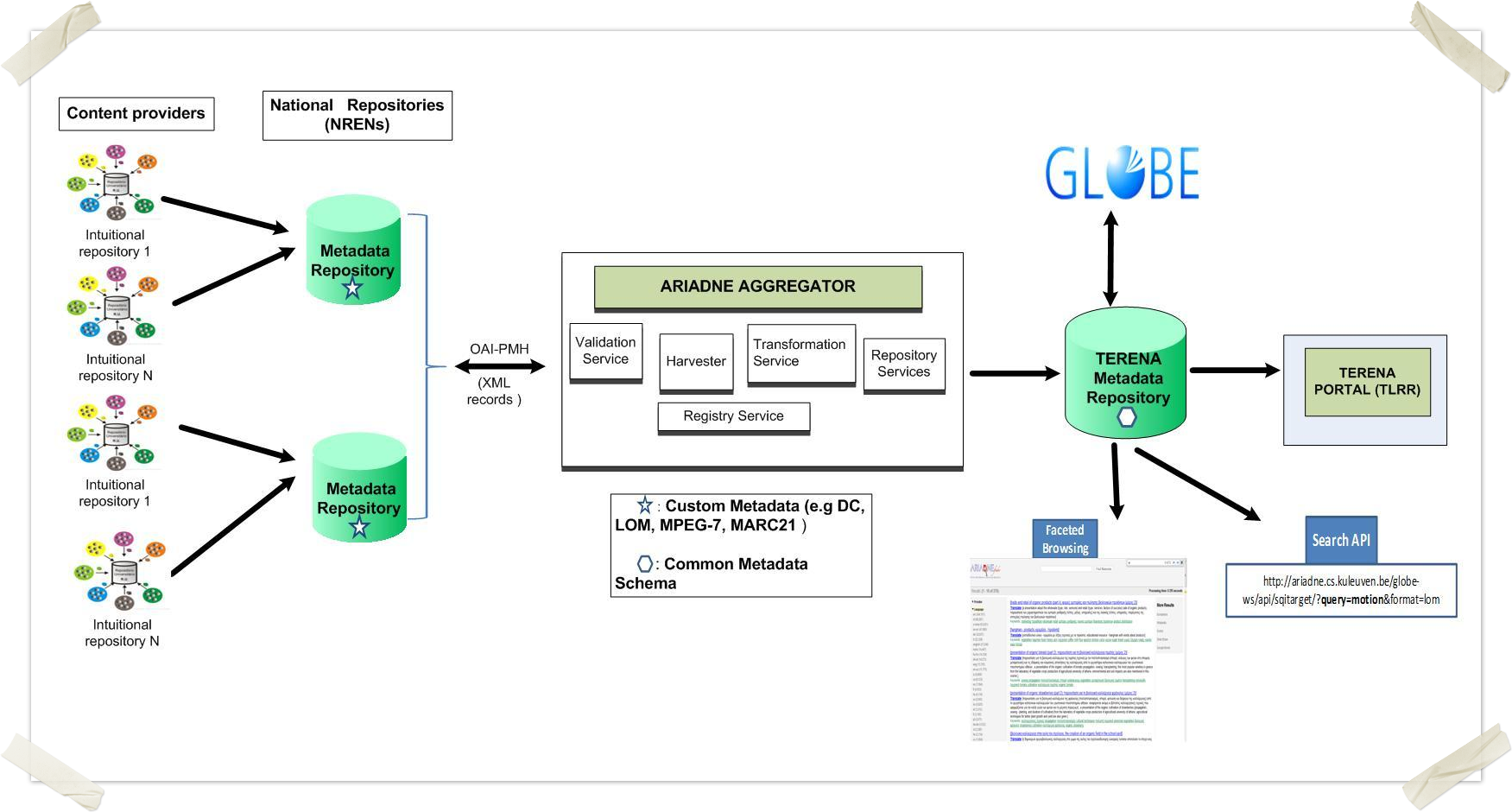
2nd VC Minutes (21 September 2012)
We've just had the second very productive discussion about the practical steps of the TF-Media Open Educational Resource portal pilot. No recordings have been made.
NOTES
21 September 2012 @ 11.00-12.30 CET.
List of participants: Zenon, Nikos, Giannis (GRNET); Carlos (UPV); Vicente (UVigo); Eli (IUCC); Jack (TAU); Peter (TERENA)
1.) MAOR-based pilot portal installation done by IUCC: http://maor.iucc.ac.il/t_materials.php?keywords=*
- Eli (IUCC) gave a brief overview about MAOR. MAOR is a national metadata and object repository used in Israel. Several institutional content repositories are attached to MAOR nationally.
- The importance of having a pan-European level repository to reach the critical mass and successfully participate in global repositories was emphasized. The layered model should include the institutional, national, pan-European and global aggregation levels.
- Eli demonstrated the pilot portal installation based on MAOR (see the screenshot)

- All the important metadata is included but not the content itself. In addition to the metadata, paradata (e.g., comments, ratings, etc.) can also be included (see on the left hand side) that is collected by the user community and added to the object.
- The participating repositories can be connected to the MAOR-based portal online via API or offline. It was mentioned that the automated, easy metadata export function is essential for the participating repositories.
- There was a question about the added value of the TERENA OER to the national repositories. Jack (TUA) explained that reaching the critical mass is important.
- Eli (IUCC) added that there are millions of contents e.g., in GLOBE and it is hard to find anything without good quality metadata (i.e. YouTube syndrome). Good quality metadata is the key although we should consider the minimum set of metadata (in the pilot) for basic search.
- The MAOR-based pilot portal is the very first, basic installation for test/demo purposes. Later on, value-added features can be implemented such as web services, APIs, inclusion of YouTube channels, etc.
- Carlos (UPV) added that the university staff (professors) can hardly be convinced to directly participate in the TERENA OER portal simply because the YouTube hits are ranked higher in Google search and universities rather upload their lectures to YouTube education channels. However, it is possible to automatically harvest metadata from the university repositories without engaging with the universities.
2.) DSpace-based portal with PuMuKit at University of Vigo
- Vicente (UVigo) gave a brief introduction to DSpace. DSpace is being used at University of Vido as as institutional repository.
- Professors are not really keen on searching materials in the repository for the moment. They prefer Google, perhaps because they only know Google.
- Stepping up from the institutional level to the national and pan-European level might help promoting better our content repositories. Filling the gap between the national level and the global level is the major role of the TERENA OER.
- TERENA OER can have value added benefits compared to Google search, such as the deeper search in metadata and the clearly licensed materials. Creative Common licensing is the potential way forward, must be added to the portal in the future.
- Eli (IUCC) commented that the service provider view is different from the end-user view. TERENA OER must be considered as a provider. Links between objects, information about who searches for what, who comments on what, etc. are all very important for the provider.
- Vicente (UVigo) noted that from the end-user point of view, added features such as embeded video player to the portal or mosaic thumbnail representation of the search targets are important. Must be considered in a later phase as enhancements.
- DSpace is only used for aggregation, no content enrichment is included. It is about the enrichment of the user experience and not the enrichment of the content itself.
- Vicente (UVigo) summarized that the DSpace-based implementation is better for institutional purposes rather than for a pan-European aggregation portal. He will contribute to the pilot with valuable comments from the end-users perspective.
- It was agreed to drop the DSpace-based implementation option!
3.) ARIADNE-based pilot portal installation done by GRNET: http://83.212.100.142:8080/terena-finder/?query=*
- Giannis (GRNET) stressed that the common metadata format and the agreement on the minimum set of metadata is important. Analysis of the metadata schemes is needed!
- Giannis will set up a mini-survey for the metadata analysis (5 questions) that can be discussed and sent out to the repository owners.
- To prof the concept, GRNET implemented an ARAIDNE-based pilot portal without engagement with the providers and without proper analysis of the harvested metadata. The OAI-PMH targets were harvested automatically from 2 providers (one Dutch and one Polish).
- Giannis demonstrated the pilot portal installation based on ARIADNE (see the screenshot)
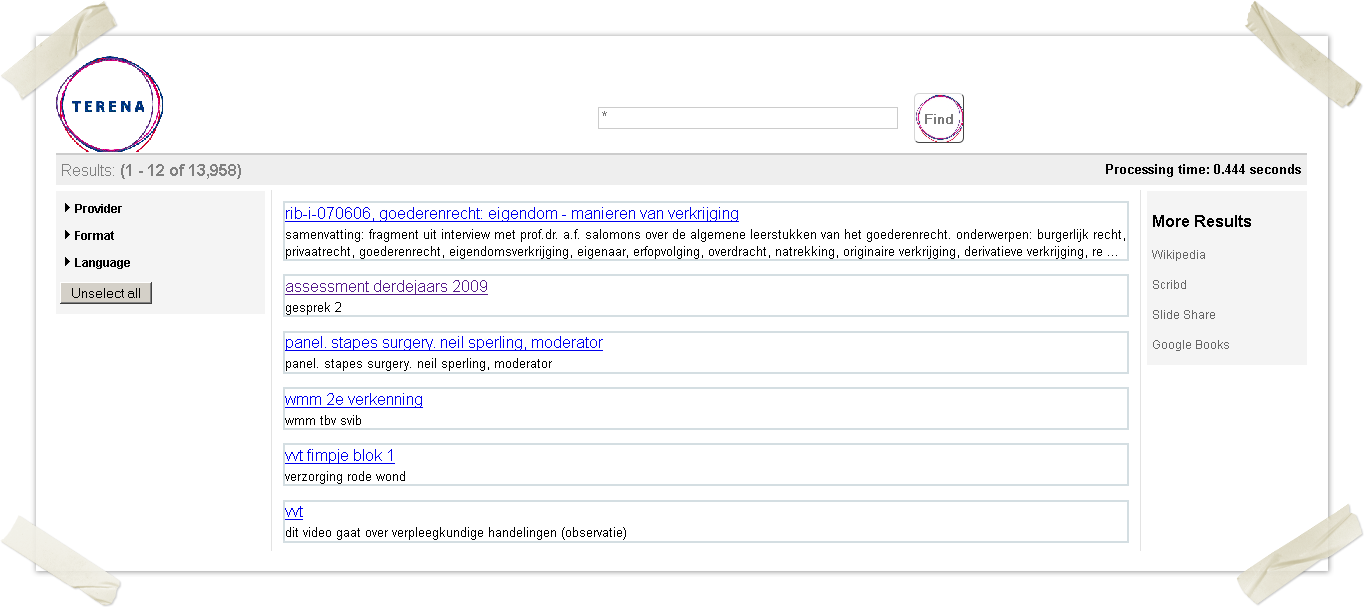
- As it can be seen from the results, the automatically harvested metadata has poor quality. Not sufficient for a pan-European aggregation portal purposes. It has been proofed and agreed that extensive metadata analysis, common metadata set agreement and engagement with the repository owners (i.e. providers) is needed.
- ARIADNE is only a specification and a set of protocols; a software stack to harvest and index metadata. It has a GoogleSerach-like user interface at the moment.
- The modular architecture helps to add new services to the portal easily.
- Peter (TERENA) said that the initial idea was to compare the MAOR-based and ARIADNE-based implementations, evaluate them with the criteria of a pan-European portal in mind, and implement the TERENA OER pilot portal based on the wining platform. Eli and Giannis commented that the two tools can even be combined as some of the features can nicely complement each other.
- Eli said that e.g., ARIADNE can be used to harvest metadata automatically from the internet (open PMH targets, YouTube channels) while MAOR can be used to harvest metadata from the national repositories engaged with the portal.
- It was agreed to dedicate the next coming meeting of the group to the discussion about how the two platform implementation can be combined.
- Peter (TERENA) will set up the next meeting and send out the open invitation to the TF-Media group.
- After the meeting Michael Stücheli (SWITCH) contacted Peter and offered to harvest metadata from the SWITCHcollection repository. Michael, Eli and Giannis were put in touch.
- Metadata information exposed by SWITCH is at https://test.collection.switch.ch/oaiprovider/?verb=ListRecords&metadataPrefix=chor_dc
- In the meantime, Eli and Giannis will try and harvest good quality metadata for both portal implementations from Greece (GRNET), Israel (IUCC), and Switzerland (SWITCH) national repositories.
- Peter (TERENA) will write a news item about the TERENA OER portal pilot and invite other national repositories to participate.
3rd VC Minutes (22 October 2012)
Date and time
Monday, 22 October 2013, at 10-12am CET
List of participants:
Zenon, Giannis (GRNET); Carlos (UPV); Vicente (Uni Vigo); Eli (IUCC); Peter (TERENA); Tiago (RNP); Antonio (ISEP); Yves (UPMC); Pantelis (Uni Athens)
Recording
http://emeeting.campusdomar.es/r_public_list/32e7d3cb8dee8f254f462fb57c1bef0a
Preliminary agenda:
- TERENA OER presentation at LAK (ISEP)
- ARIADNE update (GRNET)
- MAOR update (IUCC)
- Metadata harvesting from SWITCHcollection and others (TERENA)
- Metadata mini-survey (GRNET)
- AOB
PRE-DISCUSSION
Giannis wrote:
- The aggregation of the educational metadata could be performed at a national level following the approach of MAOR while ARIADNE technologies could be used to aggregate all the metadata records at an European/ global level. In this case MAOR instances will be harvested by ARIADNE and the Terena OER portal will be set up on the top of aggregated metadata.
- The ARIADNE based aggregator is used to harvest any available repository (open repositories with video content, youtube etc) and MAOR for national repositories. In this case we need to define how the different metadata schemas will be combined and presented in the Terena OER portal
- ARIADNE infra is used for harvesting, validating and transforming metadata from all national providers and MAOR uses the harvested records for the portal functionalities.
- Reaching a common definition of the metadata fields for the Terena-OER for all NRENs, Universities and content-provider involved, based on the LOM, the Dublin core, or similar standards. This will help us to create a common language for the metadata. This effort can be led by both ARIADNE and MAOR.
- To promote the development of the European educational portal for learning objects repository, Terena-OER portal. This portal will be one step above the national repository (NREN’s or University), and will be able to pull the Metadata to the central Terena-OER by harvesting, web services, OAI repository or batch upload. This will enable us to create the repository that suits the academic user with relevant learning object. The MAOR system can help to promote that stage, with a little modification and development, that can serve as an independent Terena-OER portal.
- After we will have the Terena-OER Portal, with a significant number of our learning objects (recording courses, simulation, animation etc.), we will connect to the GLOBE/ARIADNE/OCW-C or to any global metadata repository. We can connect to those repositories by harvesting, federated search or SQI. It is also worth noting that today, repository such as GLOBE functions as federate of federations. I think that Terena-OER can, and should be a federation.
Steps no. 1 and 2 will help us to promote the project in a way that will be tailored to the Terena end user, NRENs and Universities. In the future, step no. 3 will help us to become a part of the global federation and to increase the number of the learning objects in the repository.
1) What is the purpose of the TERENA OER portal initiative? (The motivation and the high-level architectural issue)
Fundamental questions must be clarified in a white paper about:
- how we can be different form others;
- what kind of repository we are proposing;
- what objects we are collecting;
- what tools we are planning to use;
- who the target user community is;
- how this initiative can be positioned in the context of global and other national activities
- and so on...
AGREEMENT
A paper must be drafted that summarizes the basic principles behind the TERENA OER portal initiative, gives a high-level view on the problem space in a European/global context, as well as define a common language, system architecture, and framework for recommendations. Potential issues must be addressed by the paper are:
- Dealing with multiple languages
- Understanding the users' requirements
- Supporting national repositories (with knowledge and tools)
- Aggregation of open materials
- Flexible metadata schema
- Focus on easy-to-use tools and procedures
- Understanding on existing metadata and practices already available in the community
The paper can then be agreed and presented at LAK2013 (April 2013, in Leuven Belgium) and TNC2013 (June 2013, in Maastricht, Netherlands)
ACTION 1 on Eli Shmueli (IUCC) to draft a paper (bullet points are sufficient to start with) and circulate it on the mailing list. Others are invited to contribute.
2) TERENA OER pilot implementation (The technical issue)
Proof of Concept metadata harvesting from SWITCHCollection to the MAOR test portal has been done.Look at the URL below:
Lessons learned: it is technically possible, but there are issues with both a) the metadata quality and b) the openness of content.
Other metadata to harvest:
- Vicente Goyannes (Uni Vigo) offered Campus do Mar: http://tv.campusdomar.es/oai.xml
Gytis Cibulskis (Kaunas University of Technology) offered ViPS records archive
The next steps we should take are:
- Start small with sharing and aggregating of (fully) open materials
- Look around what other projects do (in Europe, Brazil, etc.) not to reinvent the wheel.
- Promote the use of the European portal and involve in global initiatives.
AGREEMENT
A deep technical dialogue must be started among the portal technology developers (MAOR, ARIADNE), the national repository owners (SWITCHCollection, Campus do Mar, Kaunas University, etc.) and the university people representing the end-user community. The discussion should include topics as follows:
- Metadata schema for aggregation, mapping, translation, etc.
- Potential functional integration of ARIADNE (as an aggregator) and MAOR (as a portal)
- Tools, protocols, procedures, implementation options.
ACTION 2 on Peter Szegedi (TERENA) to Doodle for a technical meeting as soon as possible.
3) Mini-survey about metadata (The metadata issue)
Concerns have been shared by the attendees about the finding of good quality metadata, the willingness of content owners to improve metadata, and about the aggregation of metadata in an easy way.
AGREEMENT
University people participating in TF-Media must be our anchors in the community to figure out what's going on in this field at the national/institutional levels. What kind of metadta is generated, how that existing metadata can be exposed, what tools are there for aggregation/harvesting, etc.
ACTION 3 on Giannis Stoitsis (GRNET) to draft some questions for the mini-survey and circulate them on the mailing list. After agreement, the final set of questions can be sent to the national/institutional repository owners as well as to the academic community for gathering answers.
4th Technical VC Minutes (16 November 2012)
http://emeeting.campusdomar.es/r_public_list/32e7d3cb8dee8f254f462fb57c1bef0a
The very first milestone of the pilot project would be to make a web portal available that aggregates the OER information, facilitate content to be shared or reused, and provides a “deep search” functionality, at least. The deadline to achieve this preliminary web portal prototype would be the next coming TERENA Networking Conference in early June 2013.
Open questions for developing such a portal/system (by Eli):
- Which existing web portal platform can be used as the basis of the TERENA OER portal?
- Who is going to develop the portal (coders are needed)?
- What are the basic design requirements of such a portal?
- What metadata schema will be used by the portal?
- Who is going to host and operate the portal?
- How the web portal will connect to the back-end repository? What protocol (preferably OAI-PMH) will be used?
- How the overall system architecture will look like? How the aggregation engine (preferably ARIADNE), back-end repository (metadata only), and the front-end web portal will work together?
- What would be the target of the pilot by the TNC2013?
Some of these points have been addressed during the discussion:
- http://tv.campusdomar.es/
- https://videos.unileon.es/
- http://portal.mace-project.eu/
- http://portal.organic-edunet.eu/
- http://maor.iucc.ac.il/
- In the asynchronous mode the web portal has its own metadata store inside (like MAOR has) and the metadata can be exported-imported between the web portal and the back-end repository.
- In the synchronous case, the web portal has no memory, and there is an on-line connection between the web portal and the back-end metadata repository.
The later is preferred.
7. Eli (IUCC) is working on a paper describing the basic design and architectural principles behind the TERENA OER portal pilot project. The architectural components are as follows (by Vicente):
Content repositories || Harvesting engine <=> Metadata repository <=> API <=> Web portal
The reference harvesting engine must be connected to the web portal via standard API. Giannis (GRENT) commented that if the national/institutional content provides OAI-PMH API the metadata can be harvested (good or bad, that’s a different issue).
8. If 7-10 institutional/national repositories can be connected and about 10k (open) records can be collected (using OAI-PMH) by the TNC2013 (6 months from now) that would be a great success!
In summary, we had a very good and productive first discussion however; more detailed discussions are needed to come to the final decision about which web portal platform can actually be used as a basis of the TERENA OER portal.
5th VC Minutes (21 February, 2013)
Date and Time:
Thursday, 21 February 2013 at 16.00 CET
List of participants:
Kostas, Zenon (GRNET), Vicente (UVigo), Antonio (ISEP), Eli (IUCC), Jose-Maria (RedIRIS), Peter (TERENA), and a guest speaker Sorel Reisman (California State University, MERLOT)
Notes:
- Peter (TERENA) gave a brief update on the actual status of the TERENA TF-Media OER pilot concerning the 8 open questions listed and discussed at the previous (4th technical) meeting (see above). Peter asked for a round of updates:
- Vicente (UVigo) reported that he is working together with Giannis (GRNET) to implement the 1st "proof of concept" TERENA OER system by using software components of the two corresponding projects: Campus do Mar and ARIADNE. The pilot system will use the ARIADNE aggregation engine and metadata store as well as the PuMuKit web portal front-end. The simple metadata schema will be based on both IEEE LOM (maintained by IEEE institute) and Dublin Core (maintained by Dublin Core Metadata Initiative).
- Eli (IUCC) reported that he is willing to offer a local installation of the MAOR system to be considered as the 2nd "proof of concept" TERENA OER system for comparison. Eli introduced Prof. Sorel Reisman (California State University) who will update the meeting participants about MELOR initiative in the US.
- Jose-Maria (RedIRIS) commented that he is happy to participate with the ARCA repository however, ARCA speaks RSS only. It was said that the TERENA OER system's aggregation engine should be flexible enough to speak both RSS and OAI-PMH to the local content repositories.
- Antonio (ISEP) summarized the sub-task of the pilot group as follows: 1) architecture design, 2) pilot implementation, 3) partnership. It was agreed that the pilot implementation phase needs a common understanding on the service architecture design first. The clarification of the architecture design is the highest priority, before we start selecting software tools for implementation!
- Prof. Sorel Reisman (California State University) talked about the architecture of the MERLOT (Multimedia Educational Resources for Learning and Online Teaching) system initiated by California State University in the US. It's been developing and running for 15 year now. The service community includes both academic and industry partners. MERLOT has a three levels deep layered architecture. The web portal interface is changing as we speak, trying to be much simpler (user-friendly). The metadata aggregation is using a proprietary subset of various standards. It stores and searches metadata in several languages and can turn the search results into an RSS feed. There is a federated search in about 20 libraries connected. Several web services are available (e.g., simple search, key search, etc.), some of them are for free of charge to the academic community. MERLOT is primarily a metadata repository (participants can contribute by exposing their metadata - batch input process) but there is a brand new "content builder" function of MERLOT where content can be managed.
- Peter (TERENA) commented that the TERENA OER architecture should have as modular/layered design as the MERLOT architecture has. There should not be a competition between the UVigo+GRNET vs. IUCC implementations but a potential collaboration to a common service architecture for TERENA OER. To be able to define the details/potentials of such a technical collaboration, better understanding on the actual components and functions of both the ARIADNE and MAOR systems is needed!
Agreements:
- TERENA OER must be a stand-alone OER system that does not use ARIADNE or MAOR services but builds on the (open-source) software components developed and made available by ARIADNE and MAOR projects.
- The architecture of the TERENA OER system must be modular/layered (including the aggregation engine, metadata store, and web services) preferably combining the best of the existing tools such as ARIADNE, MAOR, PuMuKit, and others.
- In order to start implementing the TERENA OER pilot, a better/deeper understanding on the actual software tools and provided functions is needed. Therefore, Peter (TERENA) calls for a small technical meeting between Eli (IUCC), Giannis (GRNET), and Vicente (UVigo) as soon as possible. The pilot group will be informed about the outcome of the technical meeting.
6th VC Minutes (1 March, 2013)
Date: 1 March 2013 at 13.00 CET
Invited participants: Giannis (GRNET), Vicente (UVigo), Eli (IUCC), Peter (TERENA)
We've all started to converge to a common concept that we have to eventually implement as a TERENA OER.
An important intermediate milestone would be the TERENA Networking Conference (3-6 June), where three potential things will happen:
- Vicente will present the MOOC concept to the TERENA Technical Advisory Council (TAC) also mentioning the TERENA OER as one of the key building blocks.
- There will be a session dedicated to "Teaching and learning online with multimedia". Take a look at the talks accepted at https://tnc2013.terena.org/core/session/3
- We'll have chance to demonstrate the TERENA OER proof-of-concept portal over the coffee and lunch breaks.
Hopefully, these things together will set the scene and prepare the ground for an official TERENA OER pilot project approved by the TEC and funded by TERENA. This will only happen after the TERENA Networking Conference. So, our first priority would be to work towards the proof-of-concept TERENA OER to be demonstrated at TNC2013. I have identified the following actions today:
1) Peter (TERENA) to come up with the basic functional requirements for the OER web portal that might have implications on the entire aggregation architecture. To be sent to Giannis.
2) Peter (TERENA) to come up with some design principles (i.e. look and feel) for the actual web interface and/or point to an re-usable example. To be sent to Vicente.
- TERENA visual elements
- Preferable portal example: https://videos.unileon.es/
UVigo: We can prepare a mock-up that way with the TERENA look and feel but, we must wait for the metadata analysis in order to know if it will be doable, I guess.
3) Giannis (GRNET) to propose a metadata schema (potentially LOM) to be used by the proof-of-concept aggregation engine. In principle, we have to use the metadata that is available but we have to put efforts in finding the repositories that can expose 'good quality' metadata to us.
4) Giannis (GRNET) to distribute the analysis of the metadata survey. Based on that, we have to select the actual providers for the proof-of-concept (the candidates are MAOR, SURF, PSNC, UVigo, ARCA).
- TERENA harvesting report
Following the analysis of the survey we are now working on the analysis of the existing metadata provided by the candidate providers. This is connected with the paper that we are preparing for the LACRO workshop and will allow to define an element set for the LOM based metadata schema for TERENA OER. This will be ready by 1st of April. Kostas will then transform all the harvested metadata to this LOM based metadata schema that will be used by the first version of the TERENA OER portal for searching and browsing services.
5) Giannis (GRENT) to distribute the ARIADNE RESTfull API description to the group.
6) Vicente (UVigo) and Eli (IUCC) to clarify the solution how the PuMuKIT and/or the MAOR web portals can communicate with the ARIADNE RESTful API.
- We have done a proof of concept working with the ARIANE API from PuMuKIT and it runs very well. We are just waiting for the final API definition. It can be also great to have a "dummy" aggregator, with the same configuration of the final one, to test with. Maybe Giannis can help us on this.
- DRAFT service architecture (by Vicente):

7th VC Minutes (27 March, 2013)
Invited participants: Giannis, Kostas (GRNET), Vicente (UVigo), Eli (IUCC), Peter (TERENA)
Some notes and actions:
1) Eli, to come up with an Excel sheet proposing mandatory, recommended and optional metadata fields for the OER portal pilot. After several iteration rounds among us, we have to agree on a basic metadata field set that we can recommend.
2) Giannis and Kostas, to distribute the preliminary analysis of the actually harvested metadata fields from 9+ different repositories. The result of the analysis will then be checked against our recommendation in order to identify the "friendly repositories" with good enough metadata to work with.
3) Vicente, to clarify the web portal functional design based on the recommended metadata fields (1) and taking into account the result of the metadata analysis (2). Also, to send the first TERENA-branded design draft of the portal to Peter.
4) Vicente, Giannis and Kostas, to set up a virtual meeting about the technical details of the ARIADNE and PuMuKit interaction.
5) Eli, to send the target URL of the MAOR metadata exposure mechanism (the web service) to Giannis in order to harvest high quality metadata from the MAOR repository.
Further agreements:
- TERENA OER should focus on audiovisual content in the first place (having something catchy to show off). Later on, other type of materials such as data sets, papers, etc. can also be collected.
- We should focus on (work with) only 2-3 "friendly repositories" in the first place.
- We have to have information on the actual categories of the content in order to represent them into the PuMuKit-based web portal. We have to understand how different taxonomies applied by different repositories can match for instance with the UNESCO taxonomy of categories.
- Translating key words to categories or mapping different taxonomies are not trivial issues therefore out of the scope of the pilot (for now). We have to use that categories that we are getting from "friendly repositories".
- Eventually, the TERENA OER pilot can result in best practices and implementation options for those repositories that has no adequate quality metadata.
8th VC Minutes (14 May, 2013)
Participants: Giannis, Eli, Vicente, Kostas, Ruben, Peter
Referring to our discussion today, I would kindly suggest to forget about the overall system/service design and ideal architecture for a moment and let's just focus on a potential tangible demonstration that we can give at TNC2013.
The aim of the demo would be to show the potentials and benefits of a pan-European OER metadata aggregation portal via catchy multimedia contents openly available for teachers and students.
- We want potential end-users to say: Ah, I can easily find/re-use open educational multimedia resources linked to each other in a thematic structure throughout several national repositories. I can easily improve my teaching/learning experience with these.
- We also want potential content owners to say: Ah, this initiative is great, my content repository is small but joining this federation we can make our content visible as well as we can access others' relevant content easily. How can I join?
To achieve this objective we need:
1) a web portal prototype (It's already done by UVigo)
2) a metadata aggregation engine working (to show the harvesting via standard protocols)
3) at least three different national/institutional repositories with metadata fields matching to the portal needs.
The harvesting engine part is not that critical as it has no impact on the user experience during the demo. All metadat snapshots can be pre-loaded into a local database, doesn't matter. We can explain how the API-based harvesting should work.
The main question is which repositories contain the metadat fields required by the portal? The web portal needs at least:
- Title to show
- Keywords to search
- Valid URL to navigate to
- Thumbnails' URL to show (optional)
ACTIONS:
1) Eli to provide a metadata snapshot of the MAOR repository off-line (XML). This can be pre-loaded into the local portal database for the demo.
2) Vicente to make sure that the UVigo repository makes the thumbnails available for the portal.
3) Peter to figure out if and how SWITCHcollection repository makes the valid URLs available.
4) Kostas to double-check the latest metadata harvesting results against the portal's needs (4 metadata fields described above) and let us know.
Let's see if we can progress by Tuesday next week and have a VC again. Otherwise we have to postpone the demo, I'm afraid.
Latest RESULTS:
- Here you will find the portal mock-up http://terenatv.media.uvigo.es/
- And here a rough explorer of the GRNET-Ariadne database: http://terenatv.media.uvigo.es/explore.php

3)
Kostas provided the followings:
- Latest repository/metadata analysis (set of XLSs) and presentation.
- Presentation at LAK2013/LARCO conference.
- List of selected repositories for the portal prototype.
4)
Michael Stücheli (SWITCH) provided the architectural design of the Swiss national repository portal. SWITCH is happy to share knowledge with the TERENA OER pilot participants.
9th VC Minutes (9 July, 2013)
Participants: Giannis, Eli, Vicente, Kostas, Peter
Vicente said that the proof-of-concept portal works but the usability is poor due to missing metadata information such as direct URL to open content or thumbnails of multimedia resources.
Kostas also acknowledged the fact that it's hard to find the location of the matadata fields by the Ariadne harvesting engine due to the various schemas used by the repositories.
There are two ways to solve this:
- We come up with the recommendations/agreements on where to put the metadata.
- Repositories define where they put the metadata so we know where to harvest from.
Option 2 was preferred that needs no modification on the repositories' side just the creation of separate (repo schema <=> harvesting schema) mapping files per connected repositories. Note that the actual metadata field location depends on the schema used as well as on best practices (e.g., in LOM there is no trivial place for thumbnails).
It was also proposed to filer out those objects that has no correct metadata available (for instance, drop all object without a thumbnail URL available). Such a filtering can be done by the Ariadne harvesting engine.
Giannis also proposed two potential solutions for the specific thumbnail issue:
- Ask the repositories to create them and make them available (i.e. let us know where they put them).
- We can create the thumbnails at the Ariadne engine side and store them in a separate file system attached to the content URL.
Option 2 requires some development, of course. BTW, the issue of thumbnails is just one specific problem, there are other, more important issues like the availability of direct URLs to multimedia content, for instance.
A gradual approach for connected repositories can be applied as follows:
- a) Select the "friendly" repositories giving us the right metadata in a known location and format; Campusdomar, MAOR and SWITCHcollection are the candidates.
- b) Apply filtering on the Ariadne engine side to filter out objects without the metadata needed.
- c) Extend this method to other "non-friendly" repositories or maybe create thumbnails - where missing - by the engine.
Once we have agreed on the final list of friendly repositories and tested them out, we might want to re-do the metadata analysis exercise.
List of "friendly" repositories:
1) Campusdomar
- Issue: Where to put the thumbnails URL in LOM.
2) MAOR
- Issue: OAI-PMH target is needed for the Ariadne engine to harvest.
- Issue: Static XML snapshot is needed for the portal to display.
- Issue: MAOR will not provide thumbnails (needs to be created by the engine, maybe)
3) SWITCHcollection
- Issue: Content is available only after federated AAI. Ask them to make some content openly available.
4) SURFmedia
- Issue: SURFnet is not maintaining the collection any more. Maybe TERENA OER can take that over...
ACTIONS
* Get Campusdomar and MAOR working with Ariadne harvester and the Proof-of-Concept portal.
* Organise a meeting with SWITCHcollection people on making content open.
Next meeting will be on Tuesday, 23 July, 2013 at 2pm CEST.
Comments:
- perform an analysis of the metadata for MAOR and Switch
- create provider specific transformations from the provider's metadata schema to TERENA OER IEEE LOM schema
- add a filtering process at harvesting engine to filter out the metadata records that will not provide url to the actual digital resource
Next steps proposed by Vicente (UVigo):
- 1) Contact SwitchCollections and/or SurfMEDIA in order to get feeds meeting this minimum requirements
- 2) Adapt the Ariadne engine to collect from this new content providers
- 2) Ingest MAOR snapshot in the portal database or in the Ariadne engine
- 3) Analyze the metadata available in CampusdoMar, MAOR and SwitchCollections
- 4) Make a decision about facets that can be easily developed with the metadata available
- 5) Add the prototype the ability to extract thumbnails from the media if not provided
- 5) Improve the prototype and release the 1.1 version of this Proof-of-concept