Contents: | Contact details: TF-Media mailing list is at <tf-media@terena.org> TERENA PDO is Peter Szegedi <szegedi@terena.org>
|
|---|
Motivations
The TERENA task force TF-Media (2010-2013) concluded with a project plan to try and implement a European-level OER metadata repository service for the benefit of the Research and Education community gathered under TERENA/GÉANT. The fundamental principles of such a platform/service have been discussed and summarised by the task force.
There is a large interest around the global education community in establishing and maintaining OER or Learning Object (LO) repositories as exemplified by the number of existing repositories (e.g., MERLOT [2], MAOR [3], OER commons [4], Learning Resource Exchange for Schools from European Schoolnet [5]), organizations building and sustaining them (e.g., MITOpenCourseWare [6]), contributors integrating learning objects in repositories (e.g., OpenContent [7]), and users of these learning objects (e.g., Universities, Libraries). The fundamental reasons are:
- the growing educational demands in all countries,
- the limited capacity of face to face education to fulfil the demand in a timely manner (i.e. emerging MOOCs),
- the effort and cost involved to build multimedia learning materials, and the new possibilities offered by the Internet.
The main motivation for developing a metadata repository (European-level aggregation point or referatory) and an OER portal (federated single access web front-end) service would be to support the NRENs and their stakeholders (i.e. the broader TERENA/GÉANT Community) in engaging with open education by providing value-added support services.
The OER service intends to aggregate metadata (not the content) at the European-level and helps Universities and NRENs stepping to the next level (reach the critical mass e.g., in terms of the number of objects) towards exposing their OER to global repositories (such as GLOBE [9], for instance).
Aim of the pilot
The primary aim of the TERENA small project is to develop the first working prototype of the OER service (including the metadata aggregation engine and the web portal front-end) and pilot a service for the broader TERENA/GÉANT Community in 2014. The pilot service can then be taken over by the GN4 project for further technical enhancement and service development aiming to roll out in production.
The TERENA small project is to bridge the gap between the end of TF-Media (now) and the beginning of GN4 (April 2015). The reason why the idea must be tested in a TERENA small project before it’s introduced in GÉANT is the fact that the critical mass (in terms of participants, support, interest, etc.) has to be gained before any sustainable service development can be done. OER seems to be a typical “chicken-n-egg” problem at the moment (i.e. without a working prototype it’s hard to gain significant interest and without significant interest it’s hard to convince the development) therefore, the TERENA small project has to take this initiative. The OER is not the service that the NREN community is desperate to build (e.g., like the Trusted Cloud Drive pilot was in 2012) but it’s something that TERENA has to take the lead on (e.g., like the NRENum.net service pilot was in 2008) in order to facilitate the development of future value-added services on top (including MOOCs and others).
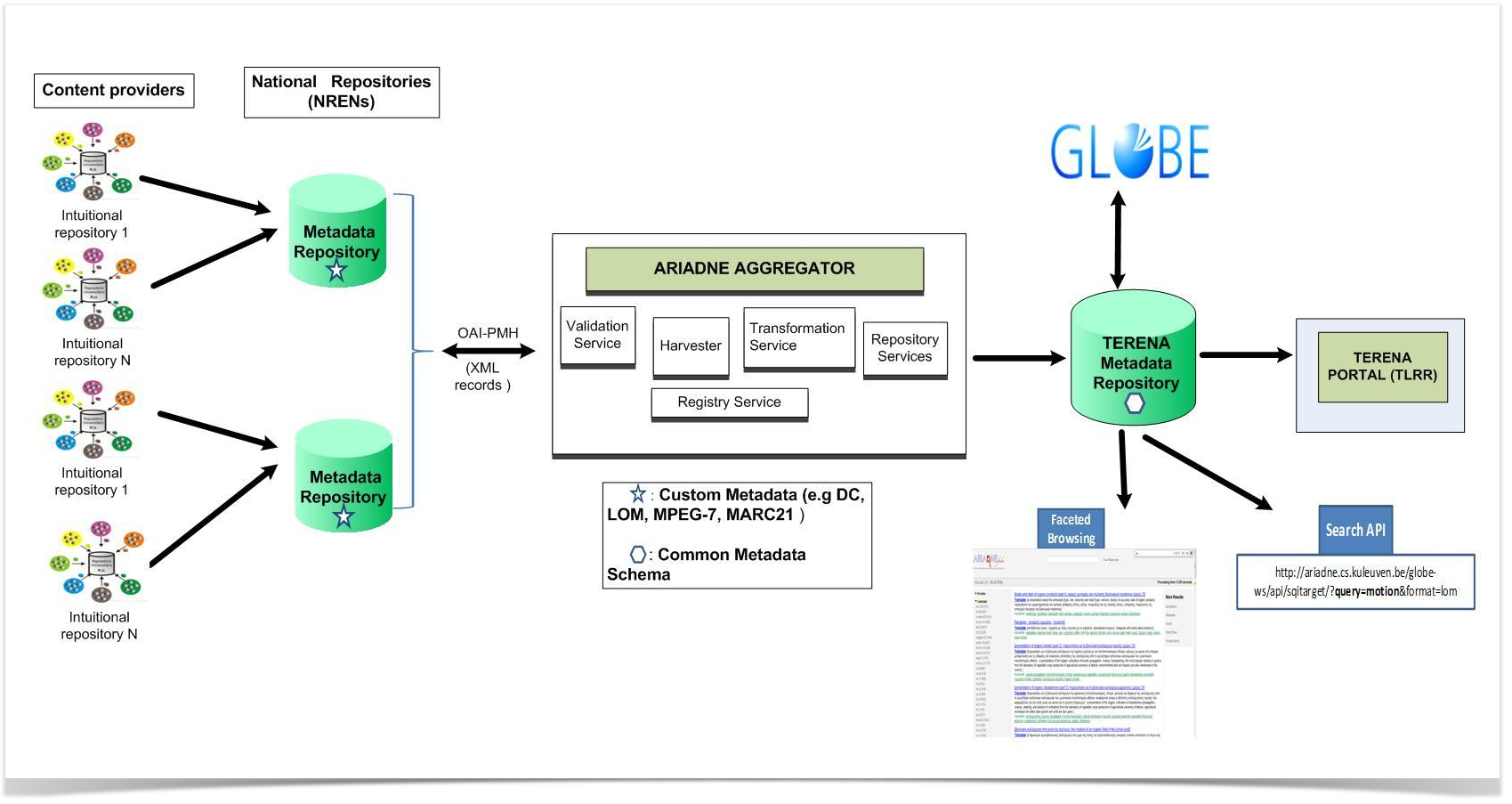
Delivering the pilot
The TERENA small project can be delivered in four tasks over 9 months (relaxed timeline):
- Definition of the minimum requirements for a common metadata schema (flexible, scalable. standard-based, etc.) taking into account the information model of the pre-selected “friendly repositories”. The potential piloting of a sample/reference repository with “good quality” metadata will also be considered by this task.
- Implementation of the ARIADNE-based metadata harvesting engine in the TERENA network.
- Development and deployment of the PuMuKit-based web portal front-end (web template).
- Integration of software components and piloting of the metadata harvesting, validating, transforming and publishing service.
More information is available in the pilot project description.
Meeting minutes
1st meeting - 28 March 2014 @ 10.00 CET
2nd meeting - 2 April 2014 @ 10.00 CEST
3rd meeting - 12 May 2014 @ 14.00 CEST
Next coming:
4th meeting - 15 May 2014 @ 11.00 CEST
3rd meeting
Attendees: Eli, Giannis, Kostas, Rui (partly), Nelson, Adam, Peter
Agenda:
- Look at the Personas
- How to transform requirements into basic features for both the engine and the web portal
- Reference repository <=> reference web portal (demonstartors)
Notes:
Peter summarised the key requirements comming from the Personas proposed at the last meeting. The group made an effort to categorise the Personas. Two main categories have been identified:
a) End-users; such as students, professors and researchers (i.e. A, B, C, D, G, K)
b) E-learning administrators; such as service managers and system/service integrators (i.e. E, F)
Giannis suggested to extract the requirements from the Personas and identify the list of "top problems" that we are trying to give an answer to.
Attendees had a consensus on writting an initial study that leads to some clear design requirements concerning both the aggregation engine (back-end) and the web protal (front-end).
Such a study must be done by mid August 2014 as the latest so that the nessesary software developments and deployments (recommended by the study) can be done by the end of the year.
Eli (IUCC) agreed to coordinate the production and delivery of such a study and Giannis (GRNET) offered to contribute to the hervesting engine related technical parts of the study. Adam (NIIF) and Nelson (FCCN) will check back whether they could also contrinute to the study, provided that the draft table of content of the study is agreed.
The attendees did a short brainstorming on the pontental content of the study. Peter suggested that the study should start with a technical overview on the state-of-the-art content repositories and their basic characteristics. Giannis said that the overall picture should also be described including similar global (e.g., GLOBE) and European (e.g., openeducationeurope.eu) initiatives and their relation to TERENA OER. The basic information model, metadata schema, and protocol set should also be suggested by the study. Contribution to the user interface and the web front-end requirememnts is nessesary. The functional description should look ahead to 3-5 years in time taking into acouint the latest trends in on-line teaching & learning .
The study must be delivered by 15 August 2014 as the latest, the harvesting engine adaptation and deployment as well as the web portal development can then go hand in hand base don the recommendations of the study.
The next meeting will be dedicated to the discussion on the Table of Content of the study.
2nd meeting
Attendees: Eli, Giannis, Rui, Adam, Peter, Nelson
Agenda:
- Personas
Recording:
http://emeeting.campusdomar.es/recording/a5fcb5b9c50cc97b644b159387021180
Notes:
Rui's personas were Adam, Bob and Charlene. Bob usually searches for materials in Google but the academic value for him is in TERENA OER. Bob is a not-so-experienced guest teacher who uses Moodle but needs some ready-to-use content. He values that Moodle that he knows reasonably well is connected to the TERENA OER. Charlene is the person at the university who teaches the teachers. Reusability of materials is important for her.
Displaying "favourite content" can help to find similar contents more easily. Ratings, registered user tracking (AAI) and social networking are important.
There is a difference between the monilithic LMS approach and the open MOOCs approach. TERENA OER should support both. Following the users' behaviour is important in case of MOOCs where they can alter from the default learning path. We need to know what they are searching for.
Eli commented that the community and social aspects are challenging. We need to focus on the repositories with good quality metadata, then allow the collection of paradata (remarks, rating, comments) and finally we can bring in the networking/social aspects.
The confidence of the users can be gained by trusted information sources, good quality metadata, additional paradata and maybe in the future a peer review system.
We should be able to integrate Moodle LMS with TERENA OER by the end of the pilot.
Next step: We need to transform the requirements (coming from the Personas) into basic features
Some administrative aspects of the pilot must be clarified:
- Roles and responsibilities of the participants (to be discussed off-line)
- TERENA funding schema (contract template will be sent by Peter)
- Community must be informed about the OER group but not yet invited (oer mailing list will be created by Peter)
Personas:
| Dean | Dean is a college professor that wants to enrich his teaching process and materials. When he searches the internet for materials for his class, he encounters several problems: Google offers many resources, but without details or depth search most of them are irrelevant; OCW-C offers full courses that he doesn't need; GLOBE is similar to Google, only it offers even more information than Google – and that information is also, at times, irrelevant. Finally, he finds the OER-Terena site. There he finds varied resources (HE repositories ) and materials. Using the depth search and the detailed metadata, he finds relevant and useful materials to enrich his class. Moreover, those resources have detailed explanations on how to use them and when. With those resources, Dean creates new teaching process that are tailored to his class topics, integrates online and offline teaching and learning. |
| Giannis | Giannis is a Data Scientist working in the National Technical University of Athens. He performs statistical analysis on big data in the medical domain. Giannis has found various references on the web about how the R package can be used for the analysis of big data. He seeks for learning resources and open courses on how R package can be used for big data analysis. He finds some interesting resources using Google and youtube but the discovery experience is not good mainly due to big recall on the queries that he performs and non relevant resources. He is also checking Coursera about available courses on this topic. The discovery process is time consuming and content is not always open. He learns about the Terena OER service and he visits the portal. At the landing page he sees different target groups and thematic categories. He is able to search using free text but also to browse content by topic, resource type, target audience. He can preview some more information (metadata) about the learning resource and access the actual learning resource (video, document, online resource). |
| Kostas | Kostas is a Software Engineer at a research center developing the tools for research projects (EU and National). He is asked to work on a new project that will deal with cloud computing and big data. He has a small previous experience with cloud computing and big data technologies. Kostas is looking for learning material on cloud computing and big data. He wants to develop his skills in cloud computing (e.g. Virtual Machines, virtualization, linux administration etc) and big data technologies (Hadoop, MongoDB, Elastic Search etc). To that end he is seeking on available course and learning material about cloud computing and big data. Although he finds interesting material using Google, youtube, coursera and sites of Universities there is no a single point at a European level that hen can access and discover such resources. The discovery process is time consuming and content is not always open. He learns about the new Terena OER service and he visits the portal. He is using the free text search functionality. When he starts typing "cloud .." the system already suggests some keywords for search. He selects a suggestion that is close to what he needs and he study the results. He is able to filter the results based on media type, audience, licenses and provider. Hen can preview the metadata of the learning resource and access the content. He can mark the content as favorite to study it later and share it with his colleagues in Facebook, twitter etc. |
| Adam | Adam - Undergraduate Student in Biology Adam wakes up every morning early. After a quick jogging in the morning he likes to go through the topics of the subjects that are being covered in class. Each day he searches on google and on the TerenaOER information about 5 key subjects that he selects for each day. On google he tries to find documental and "generic" information about the topic as it is a general search engine that will provide all sorts of type of information, from news to blogs, from assorted webpages to scientific documentation. Sometimes there are some interesting videos on Youtube or TED. But, because most academic content is under "closed" environment on LMS, Adam also searches on the TerenaOER which indexes all the information around Europe. Using the search expression he can identify other contents that are hided from Google. He also knows that this content are made from academic faculty and, of course, are much more reliable. Often he uses some of this information to his homework assignments or reviews lectures from faculty members other from his own university to grasp different viewpoints on the matter. Usually he uses his tablet to search because it is just more convenient that the laptop, but once he founds something interesting he favorites the content for later viewing on the laptop. |
| Bob | Bob - Teacher at Technical Politechnica Technical Engineer for more than 30 years now, Bob has recently joined Technical Polithecnica as a faculty member. He is very experienced user on IT and has used several times commercial services to support his training activities on his former job. But on public university context everything is different. He is supposed to use Moodle (an open source LMS), that he knows little about, to create a course to support his new course. Feeling lost, unable to find anything on the web and with little time to produce the content course. Some colleague has told him about TerenaOER website where he should be able to find useful stuff... Once he accesses the portal he searches for the content using a text expression, selects the creative commons rights, accessible content, in English (or with captions in english) ask to list first the Moodle's SCORM packages and the results start to appear. He is really impressed about the results, as they are listed from several sites across Europe. The first couple results are, in fact, packages he can introduce directly on his Moodle and tweak with. The rest are several contents that he can consult and retrieve the reference to directly use on his Moodle LMS. He favorites the content that he has used and that increases the rating of the content itself on the directory, that will help others to find this higher quality content. |
| Charlene | Charlene - e-Learning infrastructure manager at University e-Learning service at University provides a content support service to its faculty. Every day several teachers "spam" Charlene with requests to incorporate content on his courses. Un-fortunatly, most of them don't have a clue on what its needed to push content into the LMS, but the requirements are great... Charlene has given a great service over the years and people now expect interactive simulations, quizzes that are response aware and guide students,... Charlene has done lot of things in the past, but don't have much time to do it anymore. So, she tried to get some help! She joined a facebook group where people, like her, have lots of material and lots of requests, but no time to do it. But nothing really happens. References are lost, unable to get a good index, no response from others… One day, Charlene receives an e-mail from Peter Szegedi (TERENA) inviting her to look at this new site, the TerenaOER. Charlene immediately understands that this could be a great place to share her creations and, at the same time, get creations from others. She then goes to facebook and challenges her "peers" to post their content on the TerenaOER. She goes through her repository website where she has gathered all her creations and register them on the TerenaOER website. She knows that others will post also their own creations and life will be much easier for everyone in the future. She monitors her content popularity with the ranking tools provided (ranking, favorites, comments) and, times to times, she gets some feedback from teachers that have found useful content and students that have learned something new based on her creations. |
| Frans | Frans - Media services manager at Decent but Small University Frans manages the media services for the small University that includes a simple local content repository (using an open-source software) with a home-grown portal front-end tailored to the various faculties' needs. Frans really likes the media portal and its features as he was one of the lead developers of the portal and he knows everything about his local user community. Although the users are also happy with the portal but the actual contents that are available in the local repository are not so good quality and they wish to have more enriched learning objects available. Frans heard about the TERENA OER service and knows that the European level aggregation engine harvests open contents from various repositories across the community. Frans offers to contribute with the metadata of his university's contents to TERENA OER and in return he directs his home-grown portal front-end to the TERENA OER aggregation engine API in order to present more targets to the users. The well-defined API and standard protocols used make his life easier. As a result, the users will be able to use the well-know university media portal and get much better selection of contents from various providers. |
| Elen | Elen - Media services manager at Cheep University Adam is responsible for media services at his university but they have no content repository services available. Due to budget constrains, he uses YouTube for Education to store various lecture and VC recordings in the cloud. He created a dedicated YouTube channel for his university and linked other related YouTube channels to it that he found appropriate. Although most of the students are familiar with YouTube, Adam is not really satisfied by the search functionality, the lack of metadata that YouTube allows him to manage, and the fact that various commercials and irrelevant search results may pop up. Adam heard about the TERENA OER portal front-end that was tailored to multimedia content representation and found it as a much "cleaner" and streamlined solution to be provided to his users. However, Adam doesn't want to loose or migrate any of the content that he already uploaded to his YouTube channel. Luckily, the TERENA OER aggregation engine is able to harvest metadata from YouTube (among others) and present the search results in the OER portal. Adam is now happy with the new TERENA OER portal front-end and his users can actually access the very same content from YouTube as well as all the other relevant content from non-cloud based local repositories that YouTube would never be able to reference to. |
1st meeting
Attendees: Eli, Vicente, Giannis, Rui, Jack, Peter
Agenda:
- What are the SMART goals of the pilot
- How we are going to deliver the pilot
Recording:
http://emeeting.campusdomar.es/recording/838013fa539370e4d9a7d3cd3fd55361
Notes:
Virtual meetings will be held bi-weekly for the pilot participants. The delivery of the contracted tasks should be monitored more closely and frequently (at least weekly) by the person responsible for the delivery.
There was a discussion whether the 9-month pilot period is okay or too short. It basically depends on the detailed objectives (SMART goals) that we want to achieve.
The identification of the target user groups and the engagement with the professors are essential. Portal features like access to thumbnails, embedded rich media players, see what other people use, etc. are important for them.
The only demonstrator of the OER harvesting engine back-end is the portal front-end. We need to define the most important features of the portal.
An agile approach must be taken where we define some personas (user stories) first, mock-up a couple of portal examples, and define the back-end requirements to that.
Users => Portal features => Metadata schema and information model => Aggregation engine
The processing and validation of the collections (connected repositories) takes time. We also need some kind of filtering of the good quality metadata.
Moodle LMS widgets should also be incorporated into the pilot system.
The next coming meetings should focus on only one topic at a time to reduce discussion time. (Personas will be discussed next time).
KIPs
| Component | Expected outcome |
|---|---|
| TERENA OER portal |
|
| Metadata aggregation |
|
Indicator name | Expected progress |
|---|---|
Number OER content providers to be invited | 15 |
Number of content providers that will share their OER through TERENA OER | 5 |
Number of OERs shared through the OER TERENA portal | 10.000 |
Connection with global OER initiatives e.g. GLOBE | 1 |
Number of languages supported at the TERENA OER portal | 2 (EN and ES) |
Number of defined metadata compliance levels | 3 (Mandatory, Recommended, Optional) |
Dissemination activities (Presentations and publications) | 3 |